



































You are looking at the documentation of a prior release. To read the documentation of the latest release, please
visit here.
New to KubeDB? Please start here.
Database Snapshots
This tutorial will show you how to take snapshots of a KubeDB managed MongoDB database.
Note: The yaml files used in this tutorial are stored in docs/examples/mongodb folder in GitHub repository kubedb/cli.
Before You Begin
At first, you need to have a Kubernetes cluster, and the kubectl command-line tool must be configured to communicate with your cluster. If you do not already have a cluster, you can create one by using Minikube.
Now, install KubeDB cli on your workstation and KubeDB operator in your cluster following the steps here.
StorageClass is required to run KubeDB. Check the available StorageClass in cluster.
$ kubectl get storageclasses NAME PROVISIONER AGE standard (default) k8s.io/minikube-hostpath 4hA
MongoDBdatabase is needed to take snapshot for this tutorial. To keep things isolated, this tutorial uses a separate namespace calleddemothroughout this tutorial. Run the following command to prepare your cluster for this tutorial:$ kubectl create ns demo namespace/demo created $ kubedb create -f https://raw.githubusercontent.com/kubedb/cli/0.10.0/docs/examples/mongodb/snapshot/demo-1.yaml mongodb.kubedb.com/mgo-infant created
Instant Backups
You can easily take a snapshot of MongoDB database by creating a Snapshot object. When a Snapshot object is created, KubeDB operator will launch a Job that runs the mongodump command and uploads the output bson file to various cloud providers S3, GCS, Azure, OpenStack Swift and/or locally mounted volumes using osm.
In this tutorial, snapshots will be stored in a Google Cloud Storage (GCS) bucket. To do so, a secret is needed that has the following 2 keys:
| Key | Description |
|---|---|
GOOGLE_PROJECT_ID | Required. Google Cloud project ID |
GOOGLE_SERVICE_ACCOUNT_JSON_KEY | Required. Google Cloud service account json key |
$ echo -n '<your-project-id>' > GOOGLE_PROJECT_ID
$ mv downloaded-sa-json.key > GOOGLE_SERVICE_ACCOUNT_JSON_KEY
$ kubectl create secret generic mg-snap-secret -n demo \
--from-file=./GOOGLE_PROJECT_ID \
--from-file=./GOOGLE_SERVICE_ACCOUNT_JSON_KEY
secret/mg-snap-secret created
$ kubectl get secret mg-snap-secret -n demo -o yaml
apiVersion: v1
data:
GOOGLE_PROJECT_ID: PHlvdXItcHJvamVjdC1pZD4=
GOOGLE_SERVICE_ACCOUNT_JSON_KEY: ewogICJ0eXBlIjogInNlcnZpY2VfYWNjb3V...9tIgp9Cg==
kind: Secret
metadata:
creationTimestamp: "2019-02-06T06:27:36Z"
name: mg-snap-secret
namespace: demo
resourceVersion: "73604"
selfLink: /api/v1/namespaces/demo/secrets/mg-snap-secret
uid: 4b9d647b-29d8-11e9-aebf-080027875192
type: Opaque
To learn how to configure other storage destinations for Snapshots, please visit here. Now, create the Snapshot object.
apiVersion: kubedb.com/v1alpha1
kind: Snapshot
metadata:
name: snapshot-infant
namespace: demo
labels:
kubedb.com/kind: MongoDB
spec:
databaseName: mgo-infant
storageSecretName: mg-snap-secret
gcs:
bucket: kubedb-qa
$ kubedb create -f https://raw.githubusercontent.com/kubedb/cli/0.10.0/docs/examples/mongodb/snapshot/demo-2.yaml
snapshot.kubedb.com/snapshot-infant created
$ kubedb get snap -n demo
NAME DATABASENAME STATUS AGE
snapshot-infant mgo-infant Running 10s
$ kubedb get snap -n demo
NAME DATABASENAME STATUS AGE
snapshot-infant mgo-infant Succeeded 20s
$ kubedb get snap -n demo snapshot-infant -o yaml
apiVersion: kubedb.com/v1alpha1
kind: Snapshot
metadata:
creationTimestamp: "2019-02-06T06:40:07Z"
finalizers:
- kubedb.com
generation: 1
labels:
kubedb.com/kind: MongoDB
kubedb.com/name: mgo-infant
name: snapshot-infant
namespace: demo
resourceVersion: "74570"
selfLink: /apis/kubedb.com/v1alpha1/namespaces/demo/snapshots/snapshot-infant
uid: 0b20a530-29da-11e9-aebf-080027875192
spec:
databaseName: mgo-infant
gcs:
bucket: kubedb-qa
storageSecretName: mg-snap-secret
status:
completionTime: "2019-02-06T06:40:14Z"
phase: Succeeded
startTime: "2019-02-06T06:40:07Z"
Here,
metadata.labelsshould include the type of databasekubedb.com/kind: MongoDBwhose snapshot will be taken.spec.databaseNamepoints to the database whose snapshot is taken.spec.storageSecretNamepoints to the Secret containing the credentials for snapshot storage destination.spec.gcs.bucketpoints to the bucket name used to store the snapshot data.
You can also run the kubedb describe command to see the recent snapshots taken for a database.
$ kubedb describe mg -n demo mgo-infant
Name: mgo-infant
Namespace: demo
CreationTimestamp: Wed, 06 Feb 2019 12:27:01 +0600
Labels: <none>
Annotations: <none>
Replicas: 1 total
Status: Running
StorageType: Durable
Volume:
StorageClass: standard
Capacity: 1Gi
Access Modes: RWO
StatefulSet:
Name: mgo-infant
CreationTimestamp: Wed, 06 Feb 2019 12:27:01 +0600
Labels: kubedb.com/kind=MongoDB
kubedb.com/name=mgo-infant
Annotations: <none>
Replicas: 824638132588 desired | 1 total
Pods Status: 1 Running / 0 Waiting / 0 Succeeded / 0 Failed
Service:
Name: mgo-infant
Labels: kubedb.com/kind=MongoDB
kubedb.com/name=mgo-infant
Annotations: <none>
Type: ClusterIP
IP: 10.96.65.189
Port: db 27017/TCP
TargetPort: db/TCP
Endpoints: 172.17.0.7:27017
Service:
Name: mgo-infant-gvr
Labels: kubedb.com/kind=MongoDB
kubedb.com/name=mgo-infant
Annotations: service.alpha.kubernetes.io/tolerate-unready-endpoints=true
Type: ClusterIP
IP: None
Port: db 27017/TCP
TargetPort: 27017/TCP
Endpoints: 172.17.0.7:27017
Database Secret:
Name: mgo-infant-auth
Labels: kubedb.com/kind=MongoDB
kubedb.com/name=mgo-infant
Annotations: <none>
Type: Opaque
Data
====
password: 16 bytes
username: 4 bytes
Snapshots:
Name Bucket StartTime CompletionTime Phase
---- ------ --------- -------------- -----
snapshot-infant gs:kubedb-qa Wed, 06 Feb 2019 12:40:07 +0600 Wed, 06 Feb 2019 12:40:14 +0600 Succeeded
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Successful 15m MongoDB operator Successfully created Service
Normal Successful 14m MongoDB operator Successfully created StatefulSet
Normal Successful 14m MongoDB operator Successfully created MongoDB
Normal Successful 14m MongoDB operator Successfully created appbinding
Normal Successful 14m MongoDB operator Successfully patched StatefulSet
Normal Successful 14m MongoDB operator Successfully patched MongoDB
Normal Starting 1m MongoDB operator Backup running
Normal SuccessfulSnapshot 1m MongoDB operator Successfully completed snapshot
Once the snapshot Job is complete, you should see the output of the mongodump command stored in the GCS bucket.
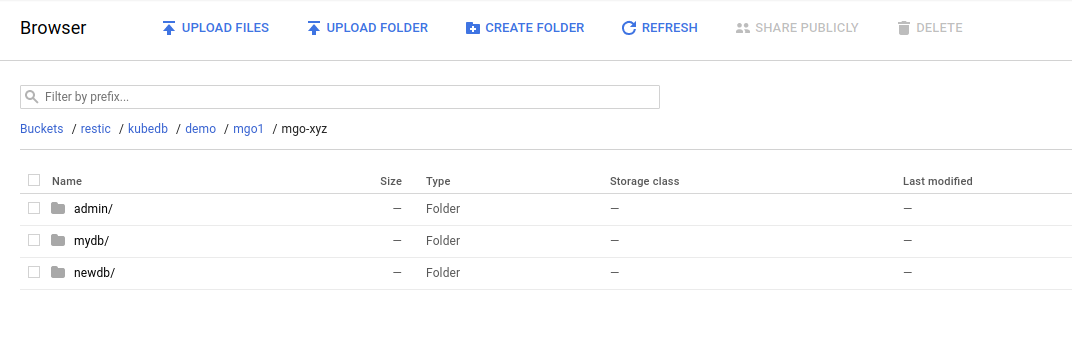
From the above image, you can see that the snapshot output is stored in a folder called {bucket}/kubedb/{namespace}/{mongodb-object}/{snapshot}/.
Restore from Snapshot
You can create a new database from a previously taken Snapshot. Specify the Snapshot name in the spec.init.snapshotSource field of a new MongoDB object. See the example mgo-recovered object below:
apiVersion: kubedb.com/v1alpha1
kind: MongoDB
metadata:
name: mgo-recovered
namespace: demo
spec:
version: "3.4-v2"
storage:
storageClassName: "standard"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
init:
snapshotSource:
name: snapshot-infant
namespace: demo
$ kubedb create -f https://raw.githubusercontent.com/kubedb/cli/0.10.0/docs/examples/mongodb/snapshot/demo-3.yaml
mongodb.kubedb.com/mgo-recovered created
Here,
spec.init.snapshotSource.namerefers to a Snapshot object for a MongoDB database in the same namespaces as this newmgo-recoveredMongoDB object.
Now, wait several seconds. KubeDB operator will create a new StatefulSet. Then KubeDB operator launches a Kubernetes Job to initialize the new database using the data from snapshot-infant Snapshot.
$ kubedb get mg -n demo
NAME VERSION STATUS AGE
mgo-infant 3.4-v2 Running 13m
mgo-recovered 3.4-v2 Initializing 57s
$ kubedb get mg -n demo
NAME VERSION STATUS AGE
mgo-infant 3.4-v2 Running 16m
mgo-recovered 3.4-v2 Running 45s
$ kubedb describe mg -n demo mgo-recovered
Name: mgo-recovered
Namespace: demo
CreationTimestamp: Wed, 06 Feb 2019 12:43:00 +0600
Labels: <none>
Annotations: kubedb.com/initialized=
Replicas: 1 total
Status: Running
StorageType: Durable
Volume:
StorageClass: standard
Capacity: 1Gi
Access Modes: RWO
StatefulSet:
Name: mgo-recovered
CreationTimestamp: Wed, 06 Feb 2019 12:43:00 +0600
Labels: kubedb.com/kind=MongoDB
kubedb.com/name=mgo-recovered
Annotations: <none>
Replicas: 824640777328 desired | 1 total
Pods Status: 1 Running / 0 Waiting / 0 Succeeded / 0 Failed
Service:
Name: mgo-recovered
Labels: kubedb.com/kind=MongoDB
kubedb.com/name=mgo-recovered
Annotations: <none>
Type: ClusterIP
IP: 10.111.0.62
Port: db 27017/TCP
TargetPort: db/TCP
Endpoints: 172.17.0.8:27017
Service:
Name: mgo-recovered-gvr
Labels: kubedb.com/kind=MongoDB
kubedb.com/name=mgo-recovered
Annotations: service.alpha.kubernetes.io/tolerate-unready-endpoints=true
Type: ClusterIP
IP: None
Port: db 27017/TCP
TargetPort: 27017/TCP
Endpoints: 172.17.0.8:27017
Database Secret:
Name: mgo-recovered-auth
Labels: kubedb.com/kind=MongoDB
kubedb.com/name=mgo-recovered
Annotations: <none>
Type: Opaque
Data
====
password: 16 bytes
username: 4 bytes
No Snapshots.
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Successful 56s MongoDB operator Successfully created Service
Normal Successful 47s MongoDB operator Successfully created StatefulSet
Normal Successful 47s MongoDB operator Successfully created MongoDB
Normal Initializing 46s MongoDB operator Initializing from Snapshot: "snapshot-infant"
Normal Successful 46s MongoDB operator Successfully patched StatefulSet
Normal Successful 46s MongoDB operator Successfully patched MongoDB
Normal SuccessfulInitialize 39s MongoDB operator Successfully completed initialization
Normal Successful 39s MongoDB operator Successfully patched StatefulSet
Normal Successful 39s MongoDB operator Successfully patched MongoDB
Normal Successful 39s MongoDB operator Successfully created appbinding
Normal Successful 39s MongoDB operator Successfully patched StatefulSet
Normal Successful 39s MongoDB operator Successfully patched MongoDB
Customizing Snapshot
You can customize pod template spec and volume claim spec for the backup and restore jobs. For details options read this doc.
Some common customization sample is shown below.
Specify PVC Template:
Backup and recovery job needs a temporary storage to hold dump files before it can be uploaded to cloud backend or inserted into database. By default, KubeDB reads storage specification from spec.storage section of database crd and creates PVC with similar specification for backup or recovery job. However, if you want to specify custom PVC template, you can do it through spec.podVolumeClaimSpec field of Snapshot crd. This is particularly helpful when you want to use different storageclass for backup or recovery job than the database.
apiVersion: kubedb.com/v1alpha1
kind: Snapshot
metadata:
name: snapshot-infant
namespace: demo
labels:
kubedb.com/kind: MongoDB
spec:
databaseName: mgo-infant
storageSecretName: mg-snap-secret
gcs:
bucket: kubedb
podVolumeClaimSpec:
storageClassName: "standard"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi # make sure size is larger or equal than your database size
Specify Resources for Backup/Recovery Job:
You can specify resources for backup or recovery job through spec.podTemplate.spec.resources field.
apiVersion: kubedb.com/v1alpha1
kind: Snapshot
metadata:
name: snapshot-infant
namespace: demo
labels:
kubedb.com/kind: MongoDB
spec:
databaseName: mgo-infant
storageSecretName: mg-snap-secret
gcs:
bucket: kubedb
podTemplate:
spec:
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
Provide Annotation for Backup/Recovery Job:
If you need to add some annotations to backup or recovery job, you can specify this in spec.podTemplate.controller.annotations. You can also specify annotation for the pod created by backup or recovery job through spec.podTemplate.annotations field.
apiVersion: kubedb.com/v1alpha1
kind: Snapshot
metadata:
name: snapshot-infant
namespace: demo
labels:
kubedb.com/kind: MongoDB
spec:
databaseName: mgo-infant
storageSecretName: mg-snap-secret
gcs:
bucket: kubedb
podTemplate:
annotations:
passMe: ToBackupJobPod
controller:
annotations:
passMe: ToBackupJob
Pass Arguments to Backup/Recovery Job:
KubeDB also allows to pass extra arguments for backup or recovery job. You can provide these arguments through spec.podTemplate.spec.args field of Snapshot crd.
apiVersion: kubedb.com/v1alpha1
kind: Snapshot
metadata:
name: snapshot-infant
namespace: demo
labels:
kubedb.com/kind: MongoDB
spec:
databaseName: mgo-infant
storageSecretName: mg-snap-secret
gcs:
bucket: kubedb
podTemplate:
spec:
args:
- --extra-args-to-backup-command
Customizing Snapshot
You can customize pod template spec and volume claim spec for backup and restore jobs. For details options read this doc.
Some common customization examples are shown below:
Specify PVC Template:
Backup and recovery jobs use temporary storage to hold dump files before it can be uploaded to cloud backend or restored into database. By default, KubeDB reads storage specification from spec.storage section of database crd and creates a PVC with similar specification for backup or recovery job. However, if you want to specify a custom PVC template, you can do it via spec.podVolumeClaimSpec field of Snapshot crd. This is particularly helpful when you want to use different storageclass for backup or recovery jobs and the database.
apiVersion: kubedb.com/v1alpha1
kind: Snapshot
metadata:
name: snapshot-infant
namespace: demo
labels:
kubedb.com/kind: MongoDB
spec:
databaseName: mgo-infant
storageSecretName: mg-snap-secret
gcs:
bucket: kubedb
podVolumeClaimSpec:
storageClassName: "standard"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi # make sure size is larger or equal than your database size
Specify Resources for Backup/Recovery Jobs:
You can specify resources for backup or recovery jobs using spec.podTemplate.spec.resources field.
apiVersion: kubedb.com/v1alpha1
kind: Snapshot
metadata:
name: snapshot-infant
namespace: demo
labels:
kubedb.com/kind: MongoDB
spec:
databaseName: mgo-infant
storageSecretName: mg-snap-secret
gcs:
bucket: kubedb
podTemplate:
spec:
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
Provide Annotations for Backup/Recovery Jobs:
If you need to add some annotations to backup or recovery jobs, you can specify those in spec.podTemplate.controller.annotations. You can also specify annotations for the pod created by backup or recovery jobs through spec.podTemplate.annotations field.
apiVersion: kubedb.com/v1alpha1
kind: Snapshot
metadata:
name: snapshot-infant
namespace: demo
labels:
kubedb.com/kind: MongoDB
spec:
databaseName: mgo-infant
storageSecretName: mg-snap-secret
gcs:
bucket: kubedb
podTemplate:
annotations:
passMe: ToBackupJobPod
controller:
annotations:
passMe: ToBackupJob
Pass Arguments to Backup/Recovery Job:
KubeDB allows users to pass extra arguments for backup or recovery jobs. You can provide these arguments through spec.podTemplate.spec.args field of Snapshot crd.
apiVersion: kubedb.com/v1alpha1
kind: Snapshot
metadata:
name: snapshot-infant
namespace: demo
labels:
kubedb.com/kind: MongoDB
spec:
databaseName: mgo-infant
storageSecretName: mg-snap-secret
gcs:
bucket: kubedb
podTemplate:
spec:
args:
- --extra-args-to-backup-command
Cleaning up
To cleanup the Kubernetes resources created by this tutorial, run:
kubectl patch -n demo mg/mgo-infant mg/mgo-recovered -p '{"spec":{"terminationPolicy":"WipeOut"}}' --type="merge"
kubectl delete -n demo mg/mgo-infant mg/mgo-recovered
kubectl patch -n demo drmn/mgo-infant drmn/mgo-recovered -p '{"spec":{"wipeOut":true}}' --type="merge"
kubectl delete -n demo drmn/mgo-infant drmn/mgo-recovered
kubectl delete ns demo
Next Steps
- See the list of supported storage providers for snapshots here.
- Take Scheduled Snapshot of MongoDB databases using KubeDB.
- Initialize MongoDB with Script.
- Initialize MongoDB with Snapshot.
- Monitor your MongoDB database with KubeDB using out-of-the-box CoreOS Prometheus Operator.
- Monitor your MongoDB database with KubeDB using out-of-the-box builtin-Prometheus.
- Use private Docker registry to deploy MongoDB with KubeDB.
- Detail concepts of MongoDB object.
- Detail concepts of MongoDBVersion object.
- Want to hack on KubeDB? Check our contribution guidelines.