



































You are looking at the documentation of a prior release. To read the documentation of the latest release, please
visit here.
New to KubeDB? Please start here.
MongoDB Sharding
Sharding is a method for distributing data across multiple machines. MongoDB uses sharding to support deployments with very large data sets and high throughput operations. This section introduces sharding in MongoDB as well as the components and architecture of sharding.
Sharded Cluster
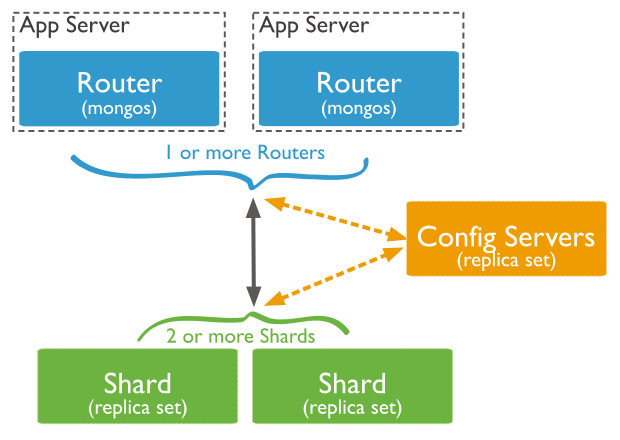
A MongoDB sharded cluster consists of the following components:
- shard: Each shard contains a subset of the sharded data. As of MongoDB 3.6, shards must be deployed as a replica set.
- mongos: The mongos acts as a query router, providing an interface between client applications and the sharded cluster.
- config servers: Config servers store metadata and configuration settings for the cluster. As of MongoDB 3.4, config servers must be deployed as a replica set (CSRS).
Shards
A shard contains a subset of data for a sharded cluster. Together, the shards of a cluster hold the entire data set for the cluster.
As of MongoDB 3.6, shards must be deployed as a replica set to provide redundancy and high availability.
Performing queries on a single shard only returns a subset of data. Connect to the mongos to perform cluster level operations, including read or write operations.
Primary Shard
Each database in a sharded cluster has a primary shard that holds all the un-sharded collections for that database. Each database has its own primary shard. The primary shard has no relation to the primary in a replica set.
The mongos selects the primary shard when creating a new database by picking the shard in the cluster that has the least amount of data. mongos uses the totalSize field returned by the listDatabase command as a part of the selection criteria.
A primary shard contains non-sharded collections as well as chunks of documents from sharded collections. Shard A is the primary shard.
Shard Status
Use the sh.status() method in the mongo shell to see an overview of the cluster. This reports includes which shard is primary for the database and the chunk distribution across the shards. See sh.status() method for more details.
Read more about shard from official document
Shard Keys
To distribute the documents in a collection, MongoDB partitions the collection using the shard key. The shard key consists of an immutable field or fields that exist in every document in the target collection.
You choose the shard key when sharding a collection. The choice of shard key cannot be changed after sharding. A sharded collection can have only one shard key. See Shard Key Specification.
To shard a non-empty collection, the collection must have an index that starts with the shard key. For empty collections, MongoDB creates the index if the collection does not already have an appropriate index for the specified shard key.
The choice of shard key affects the performance, efficiency, and scalability of a sharded cluster. A cluster with the best possible hardware and infrastructure can be bottlenecked by the choice of shard key. The choice of shard key and its backing index can also affect the sharding strategy that your cluster can use.
See the shard key documentation for more information.
Config Servers
Config servers store the metadata for a sharded cluster. The metadata reflects state and organization for all data and components within the sharded cluster. The metadata includes the list of chunks on every shard and the ranges that define the chunks.
The mongos instances cache this data and use it to route read and write operations to the correct shards. mongos updates the cache when there are metadata changes for the cluster, such as Chunk Splits or adding a shard. Shards also read chunk metadata from the config servers.
The config servers also store Authentication configuration information such as Role-Based Access Control or internal authentication settings for the cluster.
MongoDB also uses the config servers to manage distributed locks.
Read more about config servers from official document
Mongos
MongoDB mongos instances route queries and write operations to shards in a sharded cluster. mongos provide the only interface to a sharded cluster from the perspective of applications. Applications never connect or communicate directly with the shards.
The mongos tracks what data is on which shard by caching the metadata from the config servers. The mongos uses the metadata to route operations from applications and clients to the mongod instances. A mongos has no persistent state and consumes minimal system resources.
Confirm Connection to mongos Instances
To detect if the MongoDB instance that your client is connected to is mongos, use the isMaster command. When a client connects to a mongos, isMaster returns a document with a msg field that holds the string isdbgrid. For example:
{
"ismaster" : true,
"msg" : "isdbgrid",
"maxBsonObjectSize" : 16777216,
"ok" : 1,
...
}
If the application is instead connected to a mongod, the returned document does not include the isdbgrid string.
Production Configuration
In a production cluster, ensure that data is redundant and that your systems are highly available. Consider the following for a production sharded cluster deployment:
- Deploy Config Servers as a 3 member replica set
- Deploy each Shard as a 3 member replica set
- Deploy one or more mongos routers
Connecting to a Sharded Cluster
You must connect to a mongos router to interact with any collection in the sharded cluster. This includes sharded and unsharded collections. Clients should never connect to a single shard in order to perform read or write operations.
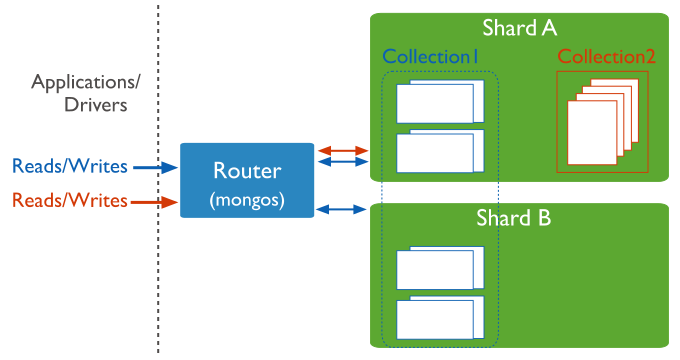
You can connect to a mongos the same way you connect to a mongod, such as via the mongo shell or a MongoDB driver.
Next Steps
- Deploy MongoDB Sharding using KubeDB.
- Detail concepts of MongoDB Sharding
- Detail concepts of MongoDB object.
- Detail concepts of MongoDBVersion object.
- Want to hack on KubeDB? Check our contribution guidelines.
NB: The images in this page are taken from MongoDB website.