



































You are looking at the documentation of a prior release. To read the documentation of the latest release, please
visit here.
New to KubeDB? Please start here.
Running PostgreSQL
This tutorial will show you how to use KubeDB to run a PostgreSQL database.
Before You Begin
At first, you need to have a Kubernetes cluster, and the kubectl command-line tool must be configured to communicate with your cluster. If you do not already have a cluster, you can create one by using Minikube.
Now, install KubeDB cli on your workstation and KubeDB operator in your cluster following the steps here.
To keep things isolated, this tutorial uses a separate namespace called demo throughout this tutorial.
This tutorial will also use a pgAdmin to connect and test PostgreSQL database, once it is running. Run the following command to prepare your cluster for this tutorial:
$ kubectl create -f ./docs/examples/postgres/demo-0.yaml
namespace "demo" created
deployment "pgadmin" created
service "pgadmin" created
$ kubectl get pods -n demo --watch
NAME READY STATUS RESTARTS AGE
pgadmin-3504868301-jmx5h 0/1 ContainerCreating 0 13s
pgadmin-3504868301-jmx5h 1/1 Running 0 41s
^C⏎
$ kubectl get service -n demo
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
pgadmin 10.99.54.130 <pending> 80:31998/TCP 10m
$ minikube ip
192.168.99.100
Now, open your browser and go to the following URL: http://{minikube-ip}:{pgadmin-svc-nodeport}. According to the above example, this URL will be http://192.168.99.100:31998. To log into the pgAdmin, use username admin and password admin.
Create a PostgreSQL database
KubeDB implements a Postgres CRD to define the specification of a PostgreSQL database. Below is the Postgres object created in this tutorial.
apiVersion: kubedb.com/v1alpha1
kind: Postgres
metadata:
name: p1
namespace: demo
spec:
version: 9.6.5
replicas: 1
doNotPause: true
storage:
storageClassName: "standard"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Mi
init:
scriptSource:
gitRepo:
repository: "https://github.com/kubedb/postgres-init-scripts.git"
directory: "."
$ kubedb create -f ./docs/examples/postgres/demo-1.yaml
validating "./docs/examples/postgres/demo-1.yaml"
postgres "p1" created
Here,
spec.versionis the version of PostgreSQL database. In this tutorial, a PostgreSQL 9.6.5 database is going to be created.spec.replicasspecifies the total number of primary and standby nodes in Postgres database cluster configuration.spec.doNotPausetells KubeDB operator that if this CRD object is deleted, it should be automatically reverted. This should be set totruefor production databases to avoid accidental deletion.spec.storagespecifies the StorageClass of PVC dynamically allocated to store data for this database. This storage spec will be passed to the StatefulSet created by KubeDB operator to run database pods. You can specify any StorageClass available in your cluster with appropriate resource requests. If no storage spec is given, anemptyDiris used.spec.init.scriptSourcespecifies scripts used to initialize the database after it is created. In this tutorial,data.sqlscript from the git repositoryhttps://github.com/kubedb/postgres-init-scripts.gitis used to create adashboardtable indataschema.
KubeDB operator watches for Postgres objects using Kubernetes api. When a Postgres object is created, KubeDB operator will create a new StatefulSet and two ClusterIP Service with the matching name. KubeDB operator will also create a governing service for StatefulSet with the name kubedb, if one is not already present. If RBAC is enabled, a ClusterRole, ServiceAccount and ClusterRoleBinding with the matching CRD object name will be created and used as the service account name for the corresponding StatefulSet.
$ kubedb describe pg -n demo p1
Name: p1
Namespace: demo
StartTimestamp: Tue, 12 Dec 2017 11:46:16 +0600
Status: Running
Init:
scriptSource:
Type: GitRepo (a volume that is pulled from git when the pod is created)
Repository: https://github.com/kubedb/postgres-init-scripts.git
Directory: .
Volume:
StorageClass: standard
Capacity: 50Mi
Access Modes: RWO
StatefulSet:
Name: p1
Replicas: 1 current / 1 desired
CreationTimestamp: Tue, 12 Dec 2017 11:46:21 +0600
Pods Status: 1 Running / 0 Waiting / 0 Succeeded / 0 Failed
Service:
Name: p1
Type: ClusterIP
IP: 10.111.209.148
Port: api 5432/TCP
Service:
Name: p1-primary
Type: ClusterIP
IP: 10.102.192.231
Port: api 5432/TCP
Database Secret:
Name: p1-auth
Type: Opaque
Data
====
.admin: 35 bytes
Topology:
Type Pod StartTime Phase
---- --- --------- -----
primary p1-0 2017-12-12 11:46:22 +0600 +06 Running
No Snapshots.
Events:
FirstSeen LastSeen Count From Type Reason Message
--------- -------- ----- ---- ---- ------ -------
5s 5s 1 Postgres operator Normal SuccessfulCreate Successfully created StatefulSet
5s 5s 1 Postgres operator Normal SuccessfulCreate Successfully created Postgres
55s 55s 1 Postgres operator Normal SuccessfulValidate Successfully validate Postgres
55s 55s 1 Postgres operator Normal Creating Creating Kubernetes objects
$ kubectl get pvc -n demo
NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE
data-p1-0 Bound pvc-d17cac3d-de60-11e7-b188-42010a800112 1Gi RWO standard 10m
$ kubectl get pv -n demo
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS AGE
pvc-d17cac3d-de60-11e7-b188-42010a800112 1Gi RWO Delete Bound demo/data-p1-0 standard 11m
$ kubectl get service -n demo
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubedb None <none> 19m
p1 10.111.209.148 <none> 5432/TCP 3m
p1-primary 10.102.192.231 <none> 5432/TCP 19m
pgadmin 10.99.54.130 <pending> 80:31998/TCP 35m
KubeDB operator sets the status.phase to Running once the database is successfully created. Run the following command to see the modified CRD object:
$ kubedb get pg -n demo p1 -o yaml
apiVersion: kubedb.com/v1alpha1
kind: Postgres
metadata:
name: p1
namespace: demo
spec:
databaseSecret:
secretName: p1-auth
doNotPause: true
init:
scriptSource:
gitRepo:
directory: .
repository: https://github.com/kubedb/postgres-init-scripts.git
replicas: 1
storage:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Mi
storageClassName: standard
version: 9.6.5
status:
creationTime: 2017-12-12T05:46:16Z
phase: Running
Please note that KubeDB operator has created a new Secret called p1-auth (format: {crd-name}-auth) for storing the password for postgres superuser. This secret contains a .admin key with a ini formatted key-value pairs. If you want to use an existing secret please specify that when creating the CRD using spec.databaseSecret.secretName.
Now, you can connect to this database from the pgAdmin dashboard using the database pod IP and postgres user password. Now, open your browser and go to the following URL: http://{minikube-ip}:{pgadmin-svc-nodeport}. To log into the pgAdmin, use username admin and password admin.
$ kubectl get pods p1-0 -n demo -o yaml | grep IP
hostIP: 192.168.99.100
podIP: 172.17.0.6
$ kubectl get secrets -n demo p1-auth -o jsonpath='{.data.\.admin}' | base64 -d
POSTGRES_PASSWORD=R9keKKRTqSJUPtNC

Continuous Archiving with wal-g
KubeDB Postgres also supports wal-g for continuous Archiving and archival restoration process. wal-g now supports only Amazon S3 as cloud storage. Below is the Postgres object created with Continuous Archiving support.
apiVersion: kubedb.com/v1alpha1
kind: Postgres
metadata:
name: p2
namespace: demo
spec:
version: 9.6.5
replicas: 2
standby: hot
doNotPause: true
archiver:
storage:
storageSecretName: s3-secret
s3:
bucket: kubedb
storage:
storageClassName: "standard"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Mi
Here,
spec.archiver.storagespecifies storage information that will be used bywal-gstorage.storageSecretNamepoints to the Secret containing the credentials for cloud storage destination.storage.s3.bucketpoints to the bucket name used to store continuous archiving data.
spec.standbyspecifies standby mode (warm/hot) supported by Postgres. [default:warm]
From the above image, you can see that continuous archiving data is stored in a folder called {bucket}/kubedb/{namespace}/{CRD object}/archive/.
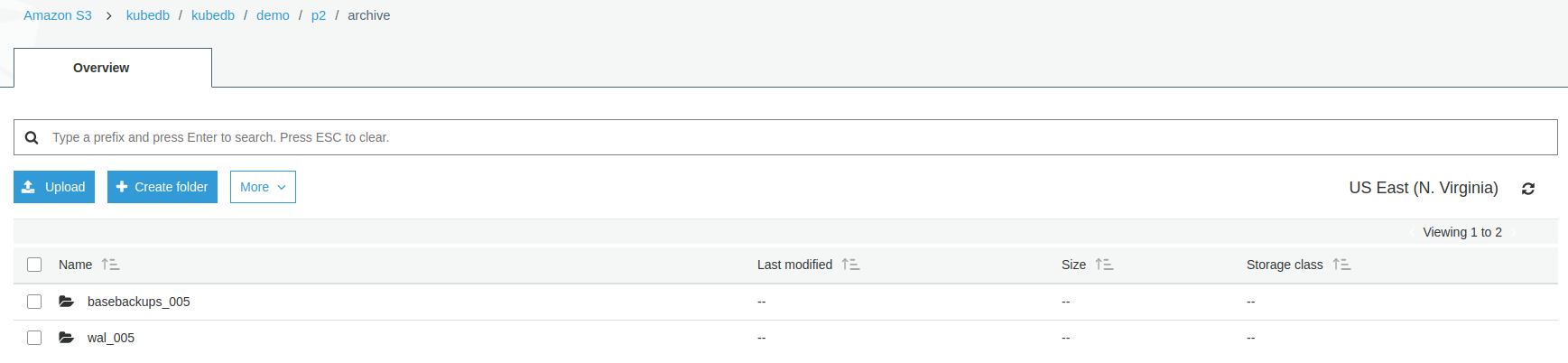
Now PostgreSQl database has started with one additional standby replica. This standby replica will be used as replication purpose and also serves read-only queries
$ kubedb describe pg -n demo p2
Topology:
Type Pod StartTime Phase
---- --- --------- -----
primary p2-0 2017-12-12 12:03:48 +0600 +06 Running
replica p2-1 2017-12-12 12:03:51 +0600 +06 Running
Now, you can connect to this database from the pgAdmin dashboard using the database pod IP and postgres user password. Open your browser and go to the following URL: http://{minikube-ip}:{pgadmin-svc-nodeport}. To log into the pgAdmin, use username admin and password admin.
$ kubectl get pods p2-0 -n demo -o yaml | grep IP
hostIP: 192.168.99.100
podIP: 172.17.0.7
$ kubectl get pods p2-1 -n demo -o yaml | grep IP
hostIP: 192.168.99.100
podIP: 172.17.0.8
$ kubectl get secrets -n demo p2-auth -o jsonpath='{.data.\.admin}' | base64 -d
POSTGRES_PASSWORD=R9keKKRTqSJUPtNC
- Hot Standby can run read-only queries.
- Warm Standby can’t accept connect and only used for replication purpose.
Automatic failover using leader election
When primary is no longer available to serve, standby replica will take control as primary. And if primary comes back, it will then act as standby replica.
Restore from WAL Archive
You can create a new database from archived data by wal-g. Specify storage information in the spec.init.postgresWAL field of a new Postgres object. Add following additional information in spec of a new Postgres:
databaseSecret:
secretName: p1-auth
init:
postgresWAL:
storageSecretName: s3-secret
s3:
endpoint: 's3.amazonaws.com'
bucket: kubedb
prefix: 'kubedb/demo/p1/archive'
This will create a new database with existing basebackup and will restore from archived wal files.
Need to use same secret of original database.
Database Snapshots
Instant Backups
Now, you can easily take a snapshot of this database by creating a Snapshot CRD object. When a Snapshot object is created, KubeDB operator will launch a Job that runs the pg_dumpall command and uploads the output sql file to various cloud providers S3, GCS, Azure, OpenStack Swift and/or locally mounted volumes using osm.
In this tutorial, snapshots will be stored in a Google Cloud Storage (GCS) bucket. To do so, a secret is needed that has the following 2 keys:
| Key | Description |
|---|---|
GOOGLE_PROJECT_ID | Required. Google Cloud project ID |
GOOGLE_SERVICE_ACCOUNT_JSON_KEY | Required. Google Cloud service account json key |
$ echo -n '<your-project-id>' > GOOGLE_PROJECT_ID
$ mv downloaded-sa-json.key > GOOGLE_SERVICE_ACCOUNT_JSON_KEY
$ kubectl create secret generic snap-secret -n demo \
--from-file=./GOOGLE_PROJECT_ID \
--from-file=./GOOGLE_SERVICE_ACCOUNT_JSON_KEY
secret "snap-secret" created
$ kubectl get secret snap-secret -n demo -o yaml
apiVersion: v1
data:
GOOGLE_PROJECT_ID: PHlvdXItcHJvamVjdC1pZD4=
GOOGLE_SERVICE_ACCOUNT_JSON_KEY: ewogICJ0eXBlIjogInNlcnZpY2VfYWNjb3V...9tIgp9Cg==
kind: Secret
metadata:
name: snap-secret
namespace: demo
type: Opaque
To lean how to configure other storage destinations for Snapshots, please visit here. Now, create the Snapshot object.
$ kubedb create -f ./docs/examples/postgres/demo-2.yaml
validating "./docs/examples/postgres/demo-2.yaml"
snapshot "p1-xyz" created
$ kubedb get snap -n demo
NAME DATABASE STATUS AGE
p1-xyz pg/p1 Running 22s
$ kubedb get snap -n demo p1-xyz -o yaml
apiVersion: kubedb.com/v1alpha1
kind: Snapshot
metadata:
labels:
kubedb.com/kind: Postgres
kubedb.com/name: p1
name: p1-xyz
namespace: demo
spec:
databaseName: p1
gcs:
bucket: kubedb
storageSecretName: snap-secret
status:
completionTime: 2017-12-11T11:43:33Z
phase: Succeeded
startTime: 2017-12-11T11:43:12Z
Here,
metadata.labelsshould include the type of databasekubedb.com/kind: Postgres.spec.databaseNamepoints to the database whose snapshot is taken.spec.storageSecretNamepoints to the Secret containing the credentials for snapshot storage destination.spec.gcs.bucketpoints to the bucket name used to store the snapshot data.
You can also run the kubedb describe command to see the recent snapshots taken for a database.
$ kubedb describe pg -n demo p1 -S=false -W=false
Name: p1
Namespace: demo
StartTimestamp: Mon, 11 Dec 2017 16:48:26 +0600
Status: Running
Topology:
Type Pod StartTime Phase
---- --- --------- -----
primary p1-0 2017-12-11 16:48:34 +0600 +06 Running
Snapshots:
Name Bucket StartTime CompletionTime Phase
---- ------ --------- -------------- -----
p1-xyz gs:kubedb Mon, 11 Dec 2017 17:43:12 +0600 Mon, 11 Dec 2017 17:43:33 +0600 Succeeded
Events:
FirstSeen LastSeen From Type Reason Message
--------- -------- ---- ---- ------ -------
2m 2m Snapshot Controller Normal SuccessfulSnapshot Successfully completed snapshot
3m 3m Snapshot Controller Normal Starting Backup running
57m 57m Postgres operator Normal SuccessfulCreate Successfully created StatefulSet
57m 57m Postgres operator Normal SuccessfulCreate Successfully created Postgres
58m 58m Postgres operator Normal SuccessfulValidate Successfully validate Postgres
58m 58m Postgres operator Normal Creating Creating Kubernetes objects
Once the snapshot Job is complete, you should see the output of the pg_dumpall command stored in the GCS bucket.
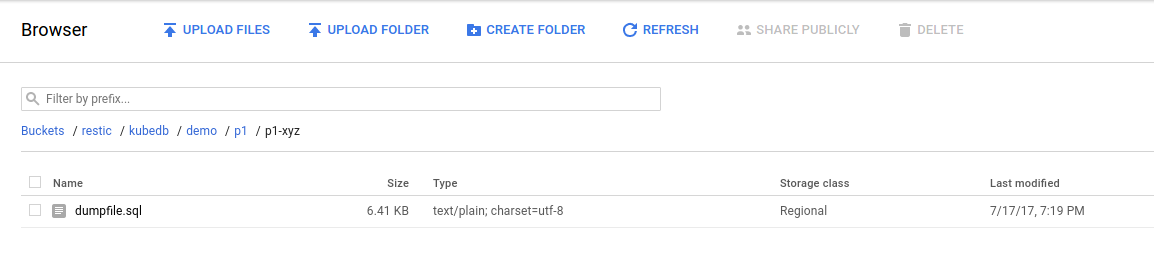
From the above image, you can see that the snapshot output is stored in a folder called {bucket}/kubedb/{namespace}/{CRD object}/{snapshot}/.
Scheduled Backups
KubeDB supports taking periodic backups for a database using a cron expression. To take periodic backups, edit the Postgres object to add following spec.backupSchedule section.
$ kubedb edit pg p1 -n demo
backupSchedule:
cronExpression: "@every 6h"
storageSecretName: snap-secret
gcs:
bucket: kubedb
Once the spec.backupSchedule is added, KubeDB operator will create a new Snapshot object on each tick of the cron expression. This triggers KubeDB operator to create a Job as it would for any regular instant backup process. You can see the snapshots as they are created using kubedb get snap command.
$ kubedb get snap -n demo
NAME DATABASE STATUS AGE
p1-20171212-092036 pg/p1 Running 1m
p1-xyz pg/p1 Succeeded 51m
Restore from Snapshot
You can create a new database from a previously taken Snapshot. Specify the Snapshot name in the spec.init.snapshotSource field of a new Postgres object. See the example recovered object below:
# See full YAML file here: /docs/examples/postgres/demo-4.yaml
databaseSecret:
secretName: p1-auth
init:
snapshotSource:
name: p1-xyz
namespace: demo
$ kubectl create -f ./docs/examples/postgres/demo-4.yaml
validating "./docs/examples/postgres/demo-4.yaml"
postgres "recovered" created
Here,
spec.init.snapshotSourcespecifies Snapshot object information to be used in restoration process.snapshotSource.namerefers to a Snapshot object namesnapshotSource.namespacerefers to a Snapshot object namespace
Now, wait several seconds. KubeDB operator will create a new StatefulSet. Then it launches a Kubernetes Job to initialize the new database using the data from p1-xyz Snapshot.
$ kubedb get pg -n demo
NAME STATUS AGE
p1 Running 10m
recovered Running 6m
$ kubedb describe pg -n demo recovered -S=false -W=false
Name: recovered
Namespace: demo
StartTimestamp: Tue, 12 Dec 2017 09:33:06 +0600
Status: Running
Init:
snapshotSource:
namespace: demo
name: p1-xyz
StatefulSet: recovered
Service: recovered, recovered-primary
Secrets: p1-auth
Topology:
Type Pod StartTime Phase
---- --- --------- -----
primary recovered-0 2017-12-12 09:52:28 +0600 +06 Running
No Snapshots.
Events:
FirstSeen LastSeen From Reason Message
--------- -------- ---- ------ -------
17s 17s Postgres operator SuccessfulInitialize Successfully completed initialization
17s 17s Postgres operator SuccessfulCreate Successfully created Postgres
37s 37s Postgres operator SuccessfulCreate Successfully created StatefulSet
37s 37s Postgres operator Initializing Initializing from Snapshot: "p1-xyz"
57s 57s Postgres operator SuccessfulValidate Successfully validate Postgres
57s 57s Postgres operator Creating Creating Kubernetes objects
Pause Database
Since the Postgres p1 has spec.doNotPause set to true, if you delete this object, KubeDB operator will recreate original Postgres object and essentially nullify the delete operation. You can see this below:
$ kubedb delete pg p1 -n demo
error: Postgres "p1" can't be paused. To continue delete, unset spec.doNotPause and retry.
Now, run kubedb edit pg p1 -n demo to set spec.doNotPause to false or remove this field (which default to false). Then if you delete the Postgres object, KubeDB operator will delete the StatefulSet and its pods, but leaves the PVCs unchanged. In KubeDB parlance, we say that p1 PostgreSQL database has entered into dormant state. This is represented by KubeDB operator by creating a matching DormantDatabase CRD object.
$ kubedb delete pg -n demo p1
postgres "p1" deleted
$ kubedb get drmn -n demo p1
NAME STATUS AGE
p1 Paused 3m
$ kubedb get drmn -n demo p1 -o yaml
apiVersion: kubedb.com/v1alpha1
kind: DormantDatabase
metadata:
annotations:
postgreses.kubedb.com/init: '{"scriptSource":{"gitRepo":{"repository":"https://github.com/kubedb/postgres-init-scripts.git"}}}'
labels:
kubedb.com/kind: Postgres
name: p1
namespace: demo
spec:
origin:
metadata:
name: p1
namespace: demo
spec:
postgres:
databaseSecret:
secretName: p1-auth
replicas: 1
storage:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Mi
storageClassName: standard
version: 9.6.5
status:
creationTime: 2017-12-12T04:22:02Z
pausingTime: 2017-12-12T04:22:12Z
phase: Paused
Here,
spec.originis the spec of the original spec of the original Postgres object.status.phasepoints to the current database statePaused.
Resume Dormant Database
To resume the database from the dormant state, set spec.resume to true in the DormantDatabase object.
$ kubedb edit drmn -n demo p1
spec:
resume: true
KubeDB operator will notice that spec.resume is set to true. KubeDB operator will delete the DormantDatabase object and create a new Postgres using the original spec. This will in turn start a new StatefulSet which will mount the originally created PVCs. Thus the original database is resumed.
Wipeout Dormant Database
You can also wipe out a DormantDatabase by setting spec.wipeOut to true. KubeDB operator will delete the PVCs, delete any relevant Snapshot for this database and also delete snapshot data stored in the Cloud Storage buckets. There is no way to resume a wiped out database. So, be sure before you wipe out a database.
$ kubedb edit drmn -n demo p1
spec:
wipeOut: true
When database is completely wiped out, you can see status WipedOut
$ kubedb get drmn -n demo
NAME STATUS AGE
p1 WipedOut 1h
Delete Dormant Database
You still have a record that there used to be a Postgres database p1 in the form of a DormantDatabase database p1. Since you have already wiped out the database, you can delete the DormantDatabase object.
$ kubedb delete drmn p1 -n demo
dormantdatabase "p1" deleted
Cleaning up
To cleanup the Kubernetes resources created by this tutorial, run:
$ kubectl delete ns demo
If you would like to uninstall KubeDB operator, please follow the steps here.
Next Steps
- Learn about the details of Postgres object here.
- See the list of supported storage providers for snapshots here.
- Thinking about monitoring your database? KubeDB works out-of-the-box with Prometheus.
- Learn how to use KubeDB in a RBAC enabled cluster.
- Wondering what features are coming next? Please visit here.
- Want to hack on KubeDB? Check our contribution guidelines.