



































You are looking at the documentation of a prior release. To read the documentation of the latest release, please
visit here.
New to KubeDB? Please start here.
KubeDB Snapshot
KubeDB operator maintains another Custom Resource Definition (CRD) for database backups called Snapshot. Snapshot object is used to take backup or restore from a backup.
Before You Begin
At first, you need to have a Kubernetes cluster, and the kubectl command-line tool must be configured to communicate with your cluster. If you do not already have a cluster, you can create one by using Minikube.
Now, install KubeDB cli on your workstation and KubeDB operator in your cluster following the steps here.
To keep things isolated, this tutorial uses a separate namespace called demo throughout this tutorial.
$ kubectl create ns demo
namespace "demo" created
$ kubectl get ns demo
NAME STATUS AGE
demo Active 5s
Note: Yaml files used in this tutorial are stored in docs/examples/elasticsearch folder in github repository kubedb/cli.
We need an Elasticsearch object in Running phase to perform backup operation.
apiVersion: kubedb.com/v1alpha1
kind: Elasticsearch
metadata:
name: infant-elasticsearch
namespace: demo
spec:
version: "5.6"
If Elasticsearch object infant-elasticsearch doesn’t exists, create it first.
$ kubedb create -f https://raw.githubusercontent.com/kubedb/cli/0.8.0/docs/examples/elasticsearch/quickstart/infant-elasticsearch.yaml
elasticsearch "infant-elasticsearch" created
$ kubedb get es -n demo infant-elasticsearch
NAME STATUS AGE
infant-elasticsearch Running 11m
Populate database
In this tutorial, we will expose ClusterIP Service infant-elasticsearch to connect database from local.
$ kubectl expose svc -n demo infant-elasticsearch --name=infant-es-exposed --port=9200 --protocol=TCP --type=NodePort
service "infant-es-exposed" exposed
Check this tutorial to see how to connect Elasticsearch.
Before taking backup, insert some data into this Elasticsearch.
export es_service=$(minikube service infant-es-exposed -n demo --url)
export es_admin_pass=$(kubectl get secrets -n demo infant-elasticsearch-auth -o jsonpath='{.data.\ADMIN_PASSWORD}' | base64 -d)
curl -XPUT --user "admin:$es_admin_pass" "$es_service/test/snapshot/1?pretty" -H 'Content-Type: application/json' -d'
{
"title": "Snapshot",
"text": "Testing instand backup",
"date": "2018/02/13"
}
'
$ curl -XGET --user "admin:$es_admin_pass" "$es_service/test/snapshot/1?pretty"
{
"_index" : "test",
"_type" : "snapshot",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"title" : "Snapshot",
"text" : "Testing instand backup",
"date" : "2018/02/13"
}
}
Now take backup of this database infant-elasticsearch.
Instant backup
Snapshot provides a declarative configuration for backup behavior in a Kubernetes native way.
Below is the Snapshot object created in this tutorial.
apiVersion: kubedb.com/v1alpha1
kind: Snapshot
metadata:
name: instant-snapshot
namespace: demo
labels:
kubedb.com/kind: Elasticsearch
spec:
databaseName: infant-elasticsearch
storageSecretName: gcs-secret
gcs:
bucket: kubedb
Here,
metadata.labelsshould include the type of database.spec.databaseNameindicates the Elasticsearch object name,infant-elasticsearch, whose snapshot is taken.spec.storageSecretNamepoints to the Secret containing the credentials for snapshot storage destination.spec.gcs.bucketpoints to the bucket name used to store the snapshot data.
In this case, kubedb.com/kind: Elasticsearch tells KubeDB operator that this Snapshot belongs to a Elasticsearch object.
Only Elasticsearch controller will handle this Snapshot object.
Note: Snapshot and Secret objects must be in the same namespace as Elasticsearch,
infant-elasticsearch.
Snapshot storage Secret
Storage Secret should contain credentials that will be used to access storage destination. In this tutorial, snapshot data will be stored in a Google Cloud Storage (GCS) bucket.
For that a storage Secret is needed with following 2 keys:
| Key | Description |
|---|---|
GOOGLE_PROJECT_ID | Required. Google Cloud project ID |
GOOGLE_SERVICE_ACCOUNT_JSON_KEY | Required. Google Cloud service account json key |
$ echo -n '<your-project-id>' > GOOGLE_PROJECT_ID
$ mv downloaded-sa-json.key > GOOGLE_SERVICE_ACCOUNT_JSON_KEY
$ kubectl create secret -n demo generic gcs-secret \
--from-file=./GOOGLE_PROJECT_ID \
--from-file=./GOOGLE_SERVICE_ACCOUNT_JSON_KEY
secret "gcs-secret" created
$ kubectl get secret -n demo gcs-secret -o yaml
apiVersion: v1
data:
GOOGLE_PROJECT_ID: PHlvdXItcHJvamVjdC1pZD4=
GOOGLE_SERVICE_ACCOUNT_JSON_KEY: ewogICJ0eXBlIjogInNlcnZpY2VfYWNjb3V...9tIgp9Cg==
kind: Secret
metadata:
creationTimestamp: 2018-02-13T06:35:36Z
name: gcs-secret
namespace: demo
resourceVersion: "4308"
selfLink: /api/v1/namespaces/demo/secrets/gcs-secret
uid: 19a77054-1088-11e8-9e42-0800271bdbb6
type: Opaque
Snapshot storage backend
KubeDB supports various cloud providers (S3, GCS, Azure, OpenStack Swift and/or locally mounted volumes) as snapshot storage backend. In this tutorial, GCS backend is used.
To configure this backend, following parameters are available:
| Parameter | Description |
|---|---|
spec.gcs.bucket | Required. Name of bucket |
spec.gcs.prefix | Optional. Path prefix into bucket where snapshot data will be stored |
An open source project osm is used to store snapshot data into cloud.
To lean how to configure other storage destinations for snapshot data, please visit here.
Now, create the Snapshot object.
$ kubedb create -f https://raw.githubusercontent.com/kubedb/cli/0.8.0/docs/examples/elasticsearch/snapshot/instant-snapshot.yaml
snapshot "instant-snapshot" created
Lets see Snapshot list of Elasticsearch infant-elasticsearch.
$ kubedb get snap -n demo --selector=kubedb.com/kind=Elasticsearch,kubedb.com/name=infant-elasticsearch
NAME DATABASE STATUS AGE
instant-snapshot es/infant-elasticsearch Succeeded 2m
KubeDB operator watches for Snapshot objects using Kubernetes API. When a Snapshot object is created, it will launch a Job that runs the elasticdump command and uploads the output files to cloud storage using osm.
Snapshot data is stored in a folder called {bucket}/{prefix}/kubedb/{namespace}/{elasticsearch}/{snapshot}/.
Once the snapshot Job is completed, you can see the output of the elasticdump command stored in the GCS bucket.
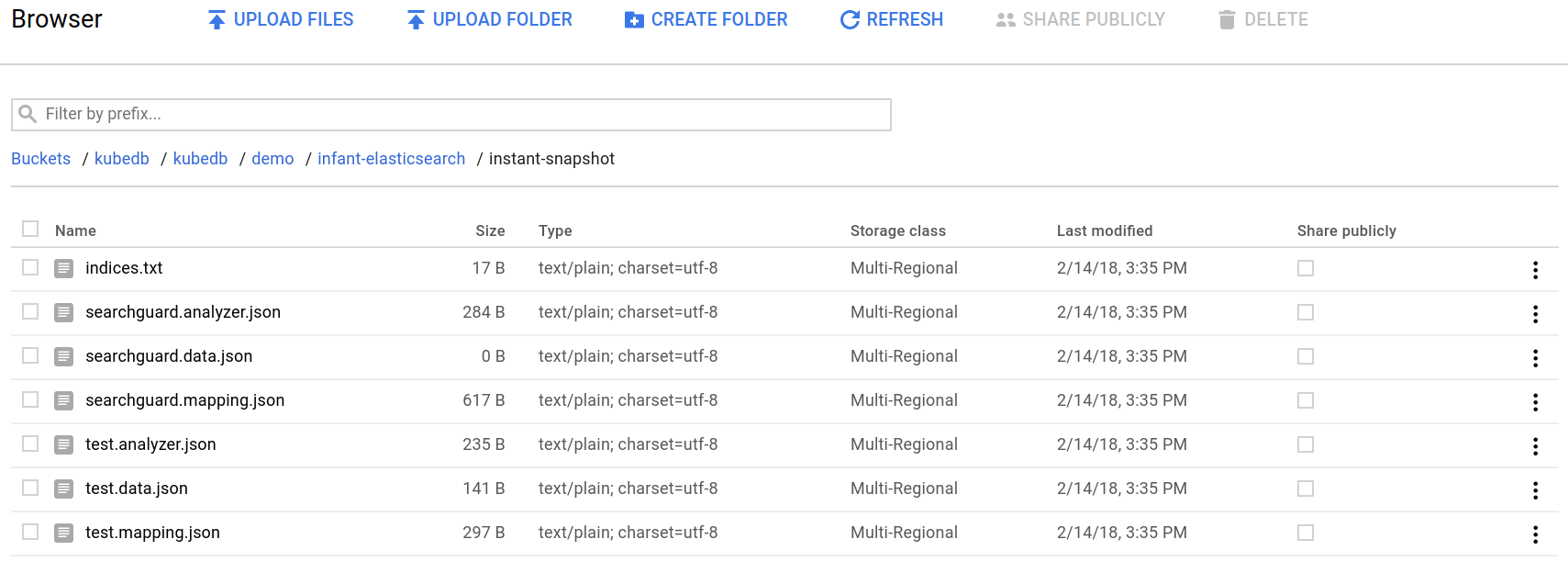
From the above image, you can see that the snapshot data files for index test are stored in your bucket.
If you open this test.data.json file, you will see the data you have created previously.
{
"_index":"test",
"_type":"snapshot",
"_id":"1",
"_score":1,
"_source":{
"title":"Snapshot",
"text":"Testing instand backup",
"date":"2018/02/13"
}
}
Lets see the Snapshot list for Elasticsearch infant-elasticsearch by running kubedb describe command.
$ kubedb describe es -n demo infant-elasticsearch -S=false -W=false
Name: infant-elasticsearch
Namespace: demo
CreationTimestamp: Tue, 13 Feb 2018 12:08:36 +0600
Status: Running
No volumes.
StatefulSet: infant-elasticsearch
Service: infant-elasticsearch, infant-elasticsearch-master, infant-es-exposed
Secrets: infant-elasticsearch-auth, infant-elasticsearch-cert
Topology:
Type Pod StartTime Phase
---- --- --------- -----
client|data|master infant-elasticsearch-0 2018-02-14 15:24:12 +0600 +06 Running
Snapshots:
Name Bucket StartTime CompletionTime Phase
---- ------ --------- -------------- -----
instant-snapshot gs:kubedb Wed, 14 Feb 2018 15:33:11 +0600 Wed, 14 Feb 2018 15:35:17 +0600 Succeeded
Events:
FirstSeen LastSeen Count From Type Reason Message
--------- -------- ----- ---- -------- ------ -------
2m 2m 1 Job Controller Normal SuccessfulSnapshot Successfully completed snapshot
4m 4m 1 Snapshot Controller Normal Starting Backup running
12m 12m 1 Elasticsearch operator Normal Successful Successfully patched Elasticsearch
12m 12m 1 Elasticsearch operator Normal Successful Successfully patched StatefulSet
12m 12m 1 Elasticsearch operator Normal Successful Successfully created Elasticsearch
13m 13m 1 Elasticsearch operator Normal Successful Successfully created StatefulSet
13m 13m 1 Elasticsearch operator Normal Successful Successfully created Service
13m 13m 1 Elasticsearch operator Normal Successful Successfully created Service
Delete Snapshot
If you want to delete snapshot data from storage, you can delete Snapshot object.
$ kubectl delete snap -n demo instant-snapshot
snapshot "instant-snapshot" deleted
Once Snapshot object is deleted, you can’t revert this process and snapshot data from storage will be deleted permanently.
Cleaning up
To cleanup the Kubernetes resources created by this tutorial, run:
$ kubectl patch -n demo es/infant-elasticsearch -p '{"spec":{"doNotPause":false}}' --type="merge"
$ kubectl delete -n demo es/infant-elasticsearch
$ kubectl patch -n demo drmn/infant-elasticsearch -p '{"spec":{"wipeOut":true}}' --type="merge"
$ kubectl delete -n demo drmn/infant-elasticsearch
$ kubectl delete ns demo
Next Steps
- See the list of supported storage providers for snapshots here.
- Learn how to schedule backup of Elasticsearch database.
- Learn about initializing Elasticsearch with Snapshot.
- Learn how to configure Elasticsearch Topology.
- Monitor your Elasticsearch database with KubeDB using
out-of-the-boxbuiltin-Prometheus. - Monitor your Elasticsearch database with KubeDB using
out-of-the-boxCoreOS Prometheus Operator. - Use private Docker registry to deploy Elasticsearch with KubeDB.
- Wondering what features are coming next? Please visit here.
- Want to hack on KubeDB? Check our contribution guidelines.