



































New to KubeDB? Please start here.
Overview
Apache Druid is a real-time analytics database designed for fast slice-and-dice analytics (“OLAP” queries) on large data sets. Druid is most often used as a database for powering use cases where real-time ingest, fast query performance, and high uptime are important. As such, Druid is commonly used for powering GUIs of analytical applications, or as a backend for highly-concurrent APIs that need fast aggregations. Druid works best with event-oriented data.
Supported Druid Features
| Features | Availability |
|---|---|
| Clustering | ✓ |
| Druid Dependency Management (MySQL, PostgreSQL and ZooKeeper) | ✓ |
| Authentication & Authorization | ✓ |
| Custom Configuration | ✓ |
| Backup/Recovery: Instant, Scheduled ( KubeStash) | ✓ |
| Monitoring with Prometheus & Grafana | ✓ |
| Builtin Prometheus Discovery | ✓ |
| Using Prometheus operator | ✓ |
| Externally manageable Auth Secret | ✓ |
| Reconfigurable Health Checker | ✓ |
| Persistent volume | ✓ |
| Dashboard ( Druid Web Console ) | ✓ |
| Automated Version Update | ✓ |
| Automatic Vertical Scaling | ✓ |
| Automated Horizontal Scaling | ✓ |
| Automated db-configure Reconfiguration | ✓ |
| TLS: Add, Remove, Update, Rotate ( Cert Manager ) | ✓ |
| Automated Reprovision | ✓ |
| Automated Volume Expansion | ✓ |
| Autoscaling (vertically) | ✓ |
Supported Druid Versions
KubeDB supports The following Druid versions.
28.0.130.0.1
The listed DruidVersions are tested and provided as a part of the installation process (ie. catalog chart), but you are open to create your own DruidVersion object with your custom Druid image.
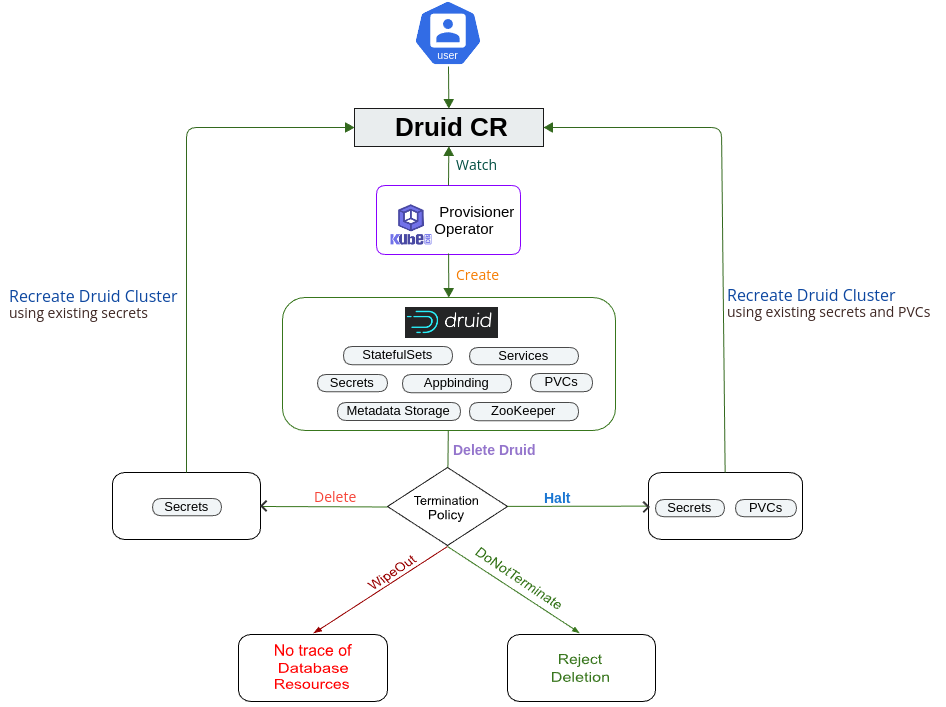
Lifecycle of Druid Object
User Guide
- Quickstart Druid with KubeDB Operator.
- Druid Clustering with KubeDB Operator.
- Backup & Restore Druid databases using KubeStash.
- Start Druid with Custom Config.
- Monitor your Druid database with KubeDB using out-of-the-box Prometheus operator.
- Monitor your Druid database with KubeDB using out-of-the-box builtin-Prometheus.
- Detail concepts of Druid object.
- Detail concepts of DruidVersion object.
- Want to hack on KubeDB? Check our contribution guidelines.