






























You are looking at the documentation of a prior release. To read the documentation of the latest release, please
visit here.
New to KubeDB? Please start here.
MySQL Group Replication
Here we’ll discuss some concepts about MySQL group replication.
So What is Replication
Replication means data being copied from the primary (the master) MySQL server to one or more secondary (the slaves) MySQL servers, instead of only stored in one server. One can use secondary servers for reads or administrative tasks. The following figure shows an example use case:
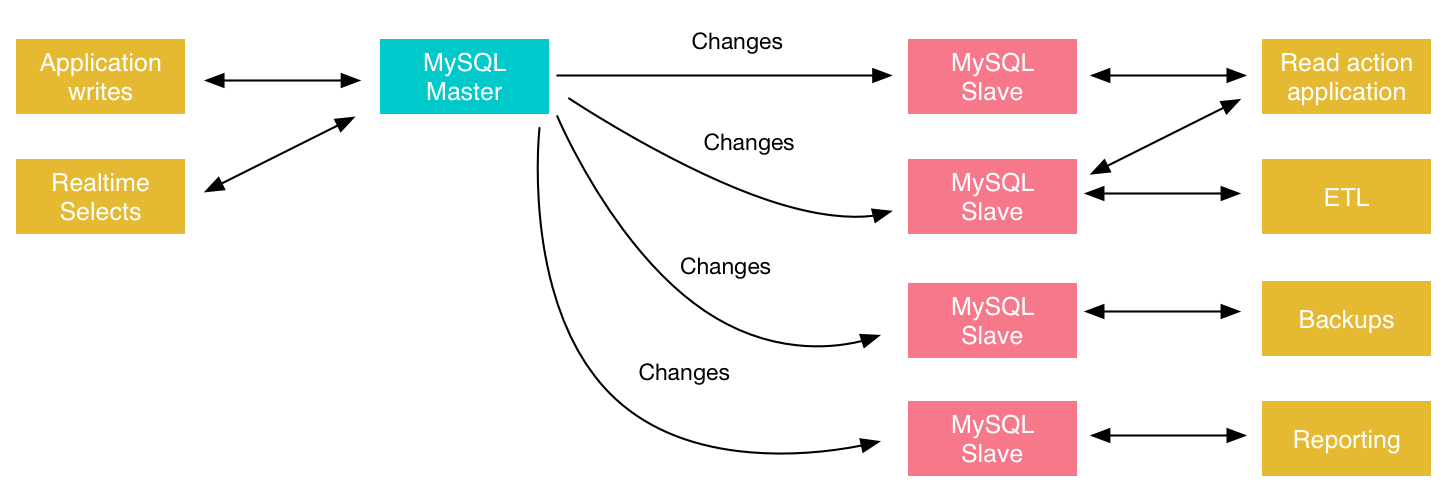
Image ref: https://www.percona.com/blog/wp-content/uploads/2017/01/replicationarchitecturexample.png
{kind=link}
Primary-Secondary Replication
It is a traditional asynchronous replication of MySQL servers in which there is a primary server and one or more secondary servers.
After receiving a transaction, the primary -
- Executes the received transaction
- Writes to the binary log with the modified data or the actual statement (based on row-based replication or statement-based replication)
- Commits the change
- Sends a response to the client application
- Sends the record from binary log to the relay logs on the secondaries before commit takes place on the primary.
Then, each of the secondaries -
- Re-executes (statement-based replication) or applies (row-based replication) the transaction
- Writes to it’s binary log
- Commits
Here, the commit on the primary and the commits on the secondaries are all independent and asynchronous.
See the following figure:
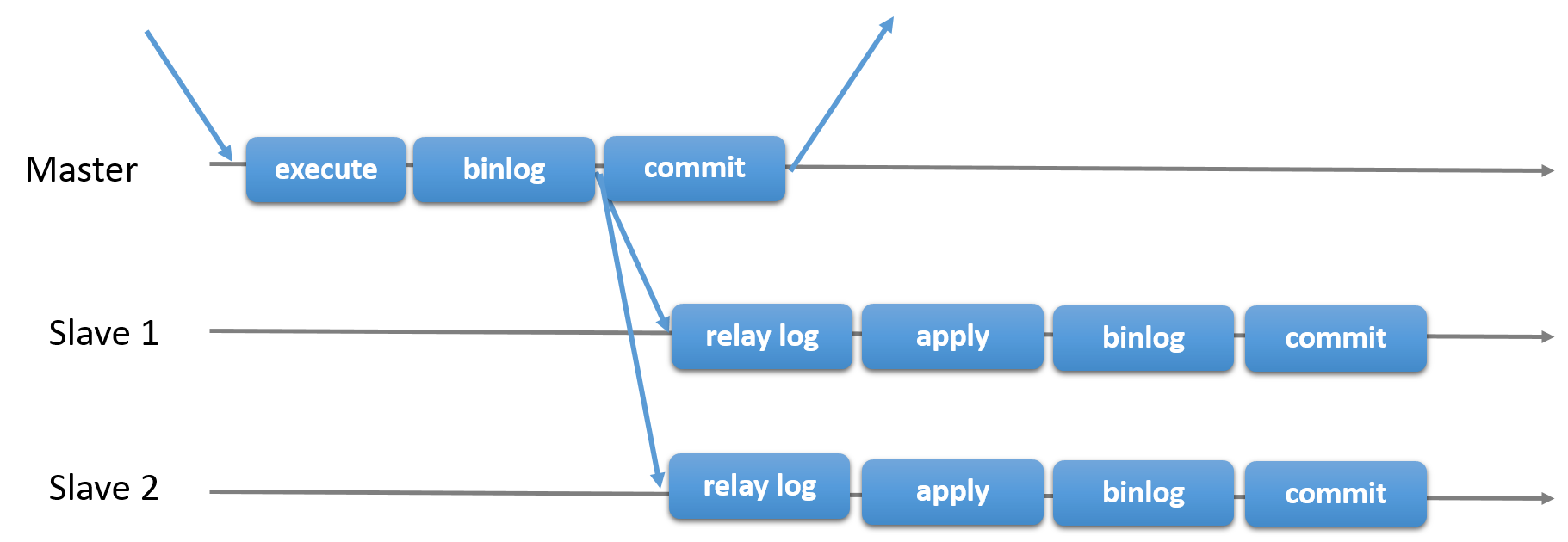
Ref: group-replication-primary-secondary-replication
MySQL Semisynchronous Replication
There is a semi-synchronous variant of the above asynchronous replication. It adds one additional synchronous step to the protocol.
After receiving a transaction, the primary -
- Executes the received transaction
- Writes to the binary log with the modified data or the actual statement (based on row-based replication or statement-based replication)
- Sends the record from binary log to the relay logs on the secondaries
- Waits for an acknowledgment from the secondaries
- Commits the transaction after getting the acknowledgment
- Sends a response to the client application
After each secondary has returned its acknowledgment
- Re-executes (statement-based replication) or applies (row-based replication) the transaction
- Writes to its binary log
- Commits
Here, the commit on the primary depends on the acknowledgment from the secondaries, but the commits on the secondaries are independent of each other and from the commit on the primary.
The following figure tells about this.
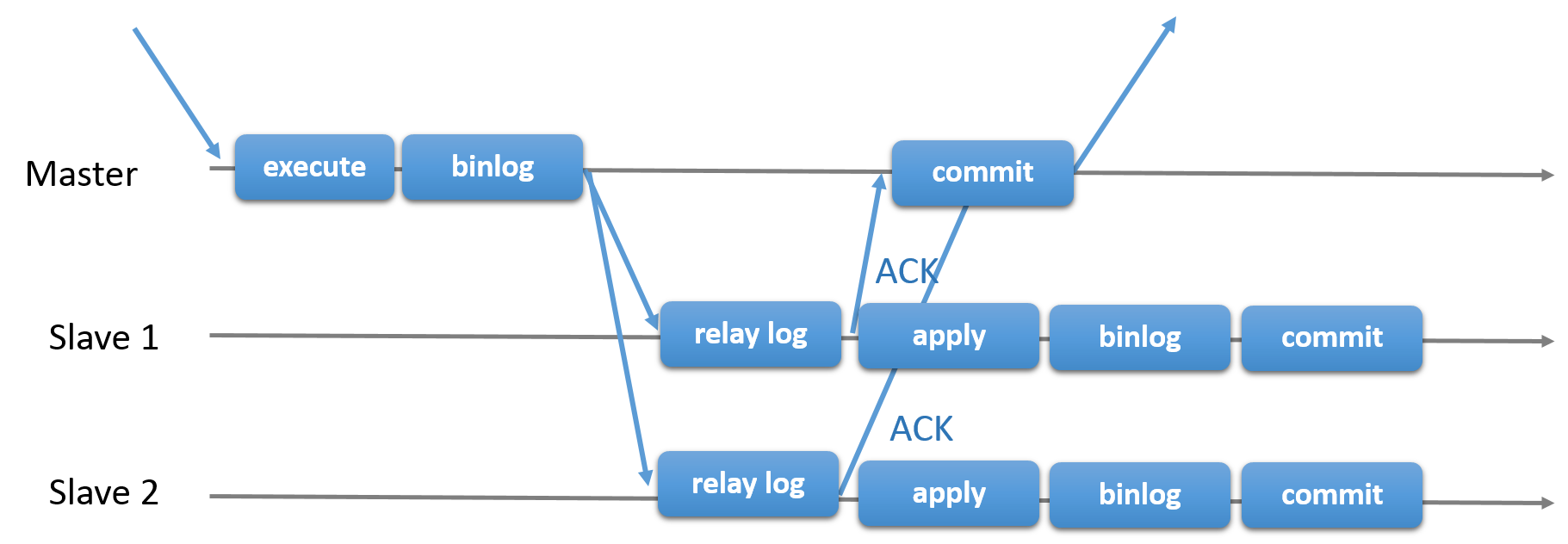
Ref: group-replication-primary-secondary-replication
Group Replication
In Group Replication, the servers keep strong coordination through message passing to build fault-tolerant system.
In a group, every server may execute transactions independently. Any read-write (RW) transaction is committed only if the group members approve it. But the read-only (RO) transactions have no restriction and so commit immediately. That means the server at which a transaction is executed sends the rows with unique identifiers to the other servers. If all servers receive these, a global total order is set for that transaction. Then all server apply the changes.
In case of a conflict (if concurrent transactions on more than one server update the same row), the certification process detects it and the group follows the first commit wins rule.
So, the whole process is as follows:
The originating server -
- Executes a transaction
- Sends a message to the group consisting of itself and other servers
- Writes the transaction to its binary log
- Commits it
- Sends a response to the client application
And the other servers -
- Write the transaction to their relay logs
- Apply it
- Write it to the binary log
- Commit it
The steps from 3 to 5 in the originating server and all the steps in the other servers are followed if all servers have reached consensus and they certify the transaction.
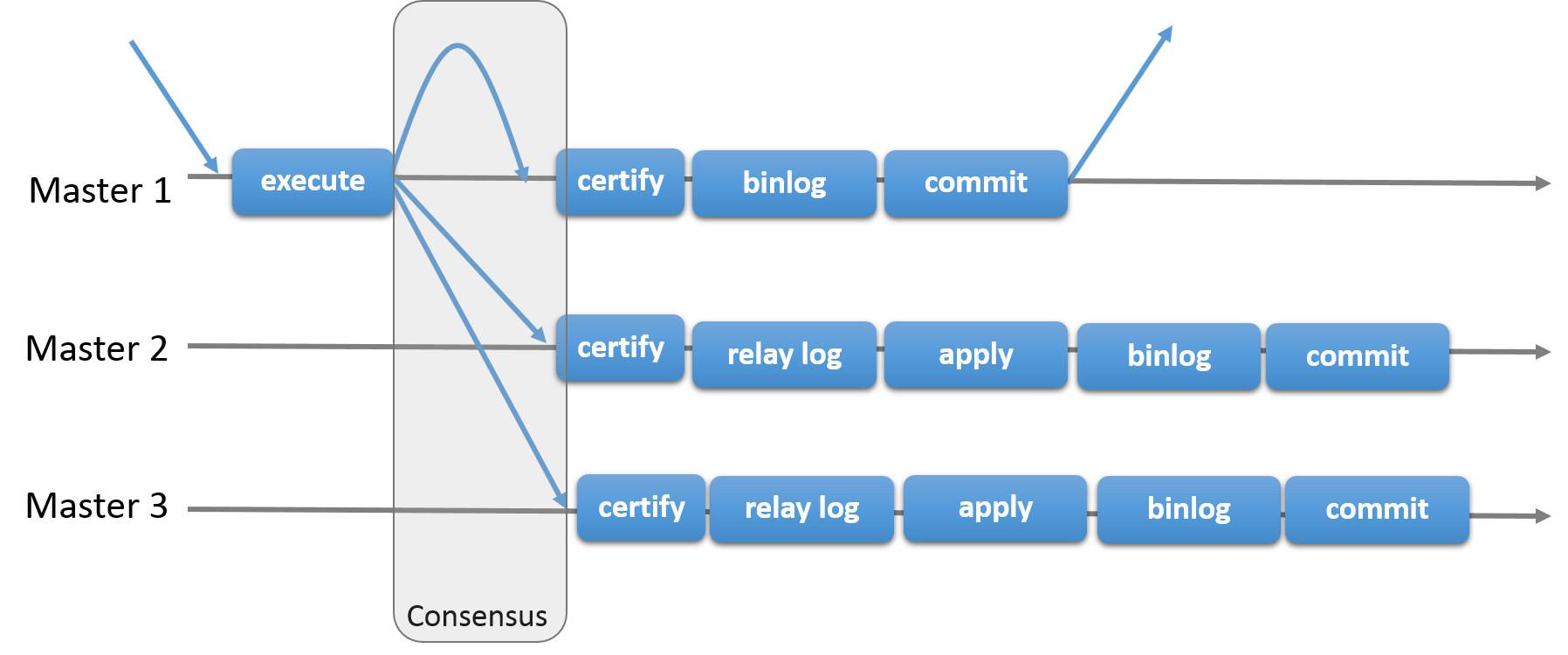
Ref: group-replication
According to Ramesh Sivaraman, QA Engineer and Kenny Gryp, MySQL Practice Manager, Oracle MySQL developed Group Replication as MySQL server plugin that provides distributed state machine replication with strong coordination among servers. Servers coordinate themselves automatically as long as they are part of the same replication group. Any server in the group can process updates. Conflicts are detected and handled automatically. There is a built-in membership service that keeps the view of the group consistent and available for all servers at any given point in time. Servers can leave and join the group and the view will be updated accordingly.
Groups can operate in a single-primary mode, where only one server accepts updates at a time. Groups can be deployed in multi-primary mode, where all servers can accept updates. Currently, we only provide the single-primary mode support for MySQL Group Replication.
A simple group architecture where three servers s1, s2, and s3 are deployed as an interconnected group and clients communicate with each of the servers has been shown below:
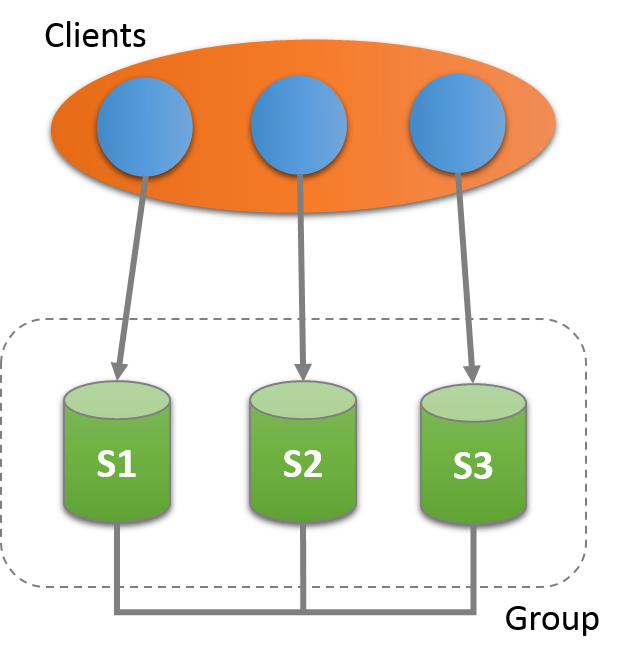
Image ref: https://dev.mysql.com/doc/refman/5.7/en/images/gr-3-server-group.png
{kind=link}
Services
Group Replication builds on some services.
Failure Detection
Basically, when server A does not receive any message from server B for a given period, then a timeout occurs and a suspicion is raised telling that server B is dead. The failure detection mechanism which is responsible for this whole process.
Group Membership
It is a built-in membership service that monitors the group. It defines the list of online servers (view) and thus the group has a consistent view of the actively participating members at a time. When servers leave and join the group and the group view will be reconfigured accordingly.
See here for more.
Fault-tolerance
MySQL Group Replication requires a majority of active servers to reach quorum and make a decision. Thus there is an impact on the failure number that a group can tolerate. So, if the majority for n is floor(n/2) + 1, then we have a relation between the group size (n) and the number of failures (f):
n = 2 x f + 1
In practice, this means that to tolerate one failure the group must have three servers in it. As such if one server fails, there are still two servers to form a majority (two out of three) and allow the system to continue to make decisions automatically and progress. However, if a second server fails involuntarily, then the group (with one server left) blocks, because there is no majority to reach a decision.
The following is a small table illustrating the formula above.
| Group Size | Majority | Instant Failures Tolerated |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
| 7 | 4 | 3 |
Ref: group-replication-fault-tolerance
Limitations
There are some limitations in MySQL Group Replication that are listed here. On top of that, though MySQL group can operate in both single-primary and multi-primary modes, we have implemented only single-primary mode. The multi-primary mode will be added in the future. See the issue MySQL Cluster.
Next Steps
- Deploy MySQL Group Replication using KubeDB.
- Want to hack on KubeDB? Check our contribution guidelines