



































You are looking at the documentation of a prior release. To read the documentation of the latest release, please
visit here.
New to KubeDB? Please start here.
Redis Cluster
Redis Cluster provides a way to partition data among multiple master nodes (data sharding) and ensures data availability. Each of the master nodes may have its own replicas. The cluster member nodes (both masters and replicas) detect failures via internal interconnection among themselves. When a majority of nodes agree with the failure of a master node, one of the replicas of the failed master node is promoted to the new master.
So basically it is a group of multiple Redis nodes where data is automatically sharded across multiple Redis nodes. And it also provides some degree of availability during partitions, that is in practical terms the ability to continue the operations when some nodes fail or are not able to communicate. However, the cluster stops to operate in the event of larger failures (for example when the majority of masters are unavailable).
So in practical terms, what do you get with Redis Cluster?
- The ability to automatically split your dataset among multiple nodes.
- The ability to continue operations when a subset of the nodes are experiencing failures or are unable to communicate with the rest of the cluster. See the reference.
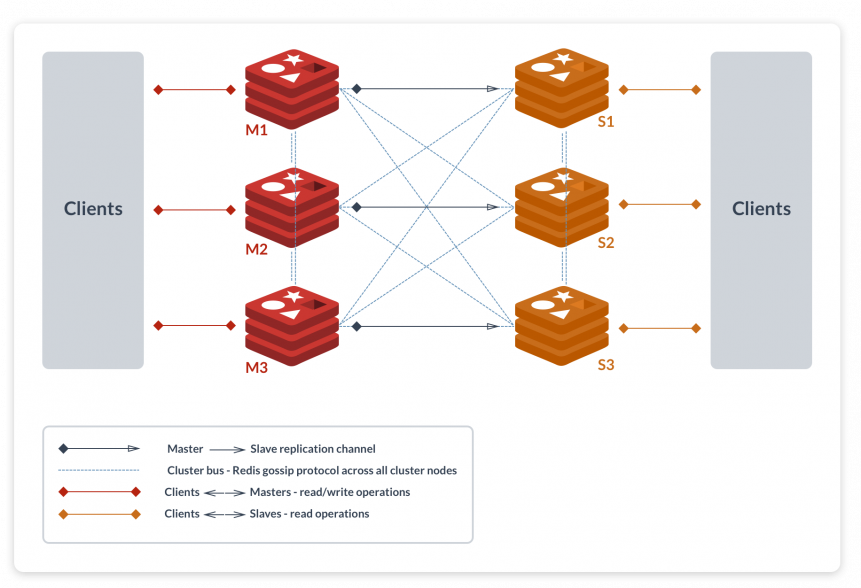
Image reference here.
Redis Cluster TCP ports
Every Redis Cluster node requires two TCP connections open. The normal Redis TCP port used to serve clients, for example 6379, plus the port obtained by adding 10000 to the data port, so 16379 in the example.
This second high port is used for the Cluster bus, that is a node-to-node communication channel using a binary protocol. The Cluster bus is used by nodes for failure detection, configuration update, failover authorization and so forth. Clients should never try to communicate with the cluster bus port, but always with the normal Redis command port, however make sure you open both ports in your firewall, otherwise Redis cluster nodes will be not able to communicate.
The command port and cluster bus port offset is fixed and is always 10000.
Note that for a Redis Cluster to work properly you need, for each node:
- The normal client communication port (usually 6379) used to communicate with clients to be open to all the clients that need to reach the cluster, plus all the other cluster nodes (that use the client port for keys migrations).
- The cluster bus port (the client port + 10000) must be reachable from all the other cluster nodes.
If you don’t open both TCP ports, your cluster will not work as expected.
The cluster bus uses a different, binary protocol, for node to node data exchange, which is more suited to exchange information between nodes using little bandwidth and processing time.
Reference: https://redis.io/topics/cluster-tutorial#redis-cluster-tcp-ports
Redis Cluster data sharding
Redis Cluster does not use consistent hashing, but a different form of sharding where every key is conceptually part of what we call a hash slot.
There are in total 16384 hash slots in Redis Cluster, and to compute what is the hash slot of a given key, it simply takes the CRC16 of the key modulo 16384.
Every node in a Redis Cluster is responsible for a subset of the hash slots, so, for example, you may have a cluster with 3 nodes, where:
- Node A contains hash slots from 0 to 5500.
- Node B contains hash slots from 5501 to 11000.
- Node C contains hash slots from 11001 to 16383.
This allows to add and remove nodes in the cluster easily. For example if one wants to add a new node D, he/she needs to move some hash slots from nodes A, B, C to D. Similarly if he/she wants to remove node A from the cluster he/she can just move the hash slots served by A to B and C. When the node A will be empty he/she can remove it from the cluster completely.
Because moving hash slots from a node to another does not require to stop operations, adding and removing nodes, or changing the percentage of hash slots hold by nodes, does not require any downtime.
Reference: https://redis.io/topics/cluster-tutorial#redis-cluster-data-sharding
Redis Cluster master-slave model
In order to ensure availability when a subset of master nodes are failing or are not able to communicate with the majority of nodes, Redis Cluster uses a master-slave model where every hash slot has from 1 (the master itself) to N replicas (N-1 additional replicas nodes).
In our example cluster with nodes A, B, C, if node B fails the cluster is not able to continue since we no longer have a way to serve hash slots in the range 5501-11000.
However when the cluster is created (or at a later time) we add a slave node to every master, so that the final cluster is composed of A, B, C those are master nodes, and A1, B1, C1 are slave nodes, the system is able to continue if node B fails.
Node B1 replicates B, and B fails, the cluster will promote node B1 as the new master and will continue to operate correctly.
However, note that if nodes B and B1 fail at the same time Redis Cluster is not able to continue to operate.
Reference: https://redis.io/topics/cluster-tutorial#redis-cluster-master-slave-model
Redis Cluster consistency guarantees
Redis Cluster is not able to guarantee strong consistency. In practical terms, this means that under certain conditions it is possible that Redis Cluster will lose writes that were acknowledged by the system to the client.
The first reason why Redis Cluster can lose writes because it uses asynchronous replication. This means that during writes the following happens:
- Your client writes to the master B.
- The master B replies OK to your client.
- The master B propagates the write to its replicas B1, B2, and B3.
As you can see B does not wait for an acknowledge from B1, B2, B3 before replying to the client, since this would be a prohibitive latency penalty for Redis, so if your client writes something, B acknowledges the write, but crashes before being able to send the write to its replicas, one of the replicas (that did not receive the write) can be promoted to master, losing the write forever.
This is very similar to what happens with most databases that are configured to flush data to disk every second, so it is a scenario you are already able to reason about because of past experiences with traditional database systems not involving distributed systems. Similarly, you can improve consistency by forcing the database to flush data on disk before replying to the client, but this usually results in prohibitively low performance. That would be the equivalent of synchronous replication in the case of Redis Cluster.
Basically, there is a trade-off to take between performance and consistency.
Redis Cluster has support for synchronous writes when absolutely needed, implemented via the WAIT command, this makes losing writes a lot less likely, however note that Redis Cluster does not implement strong consistency even when synchronous replication is used: it is always possible under more complex failure scenarios that a slave that was not able to receive the write is elected as master.
There is another notable scenario where Redis Cluster will lose writes, that happens during a network partition where a client is isolated with a minority of instances including at least a master.
Take as an example our 6 nodes cluster composed of A, B, C, A1, B1, C1, with 3 masters and 3 replicas. There is also a client, that we will call Z1.
After a partition occurs, it is possible that on one side of the partition we have A, C, A1, B1, C1, and on the other side, we have B and Z1.
Z1 is still able to write to B, that will accept its writes. If the partition heals in a very short time, the cluster will continue normally. However, if the partition lasts enough time for B1 to be promoted to master in the majority side of the partition, the writes that Z1 is sending to B will be lost.
Reference: https://redis.io/topics/cluster-tutorial#redis-cluster-consistency-guarantees
Redis Cluster configuration parameters
We are about to create an example cluster deployment. Before we continue, let’s introduce the configuration parameters that Redis Cluster introduces in the redis.conf file. Some will be obvious, others will be more clear as you continue reading.
- cluster-enabled <yes/no>: If yes enables Redis Cluster support in a specific Redis instance. Otherwise the instance starts as a stand alone instance as usual.
- cluster-config-file
: Note that despite the name of this option, this is not an user editable configuration file, but the file where a Redis Cluster node automatically persists the cluster configuration (the state, basically) every time there is a change, in order to be able to re-read it at startup. The file lists things like the other nodes in the cluster, their state, persistent variables, and so forth. Often this file is rewritten and flushed on disk as a result of some message reception. - cluster-node-timeout
: The maximum amount of time a Redis Cluster node can be unavailable, without it being considered as failing. If a master node is not reachable for more than the specified amount of time, it will be failed over by its replicas. This parameter controls other important things in Redis Cluster. Notably, every node that can’t reach the majority of master nodes for the specified amount of time, will stop accepting queries. - cluster-slave-validity-factor
: If set to zero, a slave will always try to failover a master, regardless of the amount of time the link between the master and the slave remained disconnected. If the value is positive, a maximum disconnection time is calculated as the node timeout value multiplied by the factor provided with this option, and if the node is a slave, it will not try to start a failover if the master link was disconnected for more than the specified amount of time. For example if the node timeout is set to 5 seconds, and the validity factor is set to 10, a slave disconnected from the master for more than 50 seconds will not try to failover its master. Note that any value different than zero may result in Redis Cluster to be unavailable after a master failure if there is no slave able to failover it. In that case the cluster will return back available only when the original master rejoins the cluster. - cluster-migration-barrier
: Minimum number of replicas a master will remain connected with, for another slave to migrate to a master which is no longer covered by any slave. See the appropriate section about replica migration in this tutorial for more information. - cluster-require-full-coverage <yes/no>: If this is set to yes, as it is by default, the cluster stops accepting writes if some percentage of the key space is not covered by any node. If the option is set to no, the cluster will still serve queries even if only requests about a subset of keys can be processed.
Reference: https://redis.io/topics/cluster-tutorial#redis-cluster-configuration-parameters
For more parameters, see here.
Redis Cluster main components
Keys distribution model: The key space is split into 16384 slots, effectively setting an upper limit for the cluster size of 16384 master nodes (however the suggested max size of nodes is in the order of ~ 1000 nodes).
Each master node in a cluster handles a subset of the 16384 hash slots. The cluster is stable when there is no cluster reconfiguration in progress (i.e. where hash slots are being moved from one node to another). When the cluster is stable, a single hash slot will be served by a single node (however the serving node can have one or more replicas that will replace it in the case of net splits or failures, and that can be used in order to scale read operations where reading stale data is acceptable).
Reference: https://redis.io/topics/cluster-spec#keys-distribution-model
Keys hash tags: There is an exception for the computation of the hash slot that is used in order to implement hash tags. Hash tags are a way to ensure that multiple keys are allocated in the same hash slot. This is used in order to implement multi-key operations in Redis Cluster.
Reference: https://redis.io/topics/cluster-spec#keys-hash-tags
Cluster nodes’ attributes: Every node has a unique name in the cluster. The node name is the hex representation of a 160 bit random number, obtained the first time a node is started (usually using /dev/urandom). The node will save its ID in the node configuration file, and will use the same ID forever, or at least as long as the node configuration file is not deleted by the system administrator, or a hard reset is requested via the CLUSTER RESET command.
A detailed explanation of all the node fields is described in the CLUSTER NODES documentation.
The following is sample output of the CLUSTER NODES command sent to a master node in a small cluster of three nodes.
$ redis-cli cluster nodes d1861060fe6a534d42d8a19aeb36600e18785e04 127.0.0.1:6379 myself - 0 1318428930 1 connected 0-1364 3886e65cc906bfd9b1f7e7bde468726a052d1dae 127.0.0.1:6380 master - 1318428930 1318428931 2 connected 1365-2729 d289c575dcbc4bdd2931585fd4339089e461a27d 127.0.0.1:6381 master - 1318428931 1318428931 3 connected 2730-4095Reference: https://redis.io/topics/cluster-spec#cluster-nodes-attributes
The Cluster bus: Every Redis Cluster node has an additional TCP port for receiving incoming connections from other Redis Cluster nodes. This port is at a fixed offset from the normal TCP port used to receive incoming connections from clients. To obtain the Redis Cluster port, 10000 should be added to the normal commands port. For example, if a Redis node is listening for client connections on port 6379, the Cluster bus port 16379 will also be opened.
Reference: https://redis.io/topics/cluster-spec#the-cluster-bus
Cluster topology: Redis Cluster is a full mesh where every node is connected with every other node using a TCP connection.
In a cluster of N nodes, every node has N-1 outgoing TCP connections and N-1 incoming connections.
These TCP connections are kept alive all the time and are not created on demand. When a node expects a pong reply in response to a ping in the cluster bus, before waiting long enough to mark the node as unreachable, it will try to refresh the connection with the node by reconnecting from scratch.
Reference: https://redis.io/topics/cluster-spec#cluster-topology
Nodes handshake: Nodes always accept connections on the cluster bus port, and even reply to pings when received, even if the pinging node is not trusted. However, all other packets will be discarded by the receiving node if the sending node is not considered part of the cluster.
A node will accept another node as part of the cluster only in two ways:
If a node presents itself with a
MEETmessage. A meet message is exactly like a PING message but forces the receiver to accept the node as part of the cluster. Nodes will sendMEETmessages to other nodes only if the system administrator requests this via the following command:$ CLUSTER MEET ip portA node will also register another node as part of the cluster if a node that is already trusted will gossip about this other node. So if A knows B, and B knows C, eventually B will send gossip messages to A about C. When this happens, A will register C as part of the network, and will try to connect with C.
Reference: https://redis.io/topics/cluster-spec#nodes-handshake
Next Steps
- Deploy Redis Cluster using KubeDB.
- Detail concepts of Redis object.
- Detail concepts of RedisVersion object.
- Want to hack on KubeDB? Check our contribution guidelines.