



































You are looking at the documentation of a prior release. To read the documentation of the latest release, please
visit here.
New to KubeDB? Please start here.
New to KubeDB? Please start here.
Configure Druid Cluster
In Druid cluster, there are six nodes available coordinators, overlords, brokers, routers, historicals, middleManagers. In this tutorial, we will see how to configure each node of a druid cluster.
Before You Begin
At first, you need to have a Kubernetes cluster, and the
kubectlcommand-line tool must be configured to communicate with your cluster. If you do not already have a cluster, you can create one by using kind.Now, install KubeDB cli on your workstation and KubeDB operator in your cluster following the steps here and make sure to include the flags
--set global.featureGates.Druid=trueto ensure Druid CRD and--set global.featureGates.ZooKeeper=trueto ensure ZooKeeper CRD as Druid depends on ZooKeeper for external dependency with helm command.To keep things isolated, this tutorial uses a separate namespace called
demothroughout this tutorial.
$ kubectl create namespace demo
namespace/demo created
$ kubectl get namespace
NAME STATUS AGE
demo Active 9s
Note: YAML files used in this tutorial are stored in here in GitHub repository kubedb/docs.
Find Available StorageClass
We will have to provide StorageClass in Druid CR specification. Check available StorageClass in your cluster using the following command,
$ kubectl get storageclass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
standard (default) rancher.io/local-path Delete WaitForFirstConsumer false 1h
Here, we have standard StorageClass in our cluster from Local Path Provisioner.
Before deploying Druid cluster, we need to prepare the external dependencies.
Create External Dependency (Deep Storage)
Before proceeding further, we need to prepare deep storage, which is one of the external dependency of Druid and used for storing the segments. It is a storage mechanism that Apache Druid does not provide. Amazon S3, Google Cloud Storage, or Azure Blob Storage, S3-compatible storage (like Minio), or HDFS are generally convenient options for deep storage.
In this tutorial, we will run a minio-server as deep storage in our local kind cluster using minio-operator and create a bucket named druid in it, which the deployed druid database will use.
$ helm repo add minio https://operator.min.io/
$ helm repo update minio
$ helm upgrade --install --namespace "minio-operator" --create-namespace "minio-operator" minio/operator --set operator.replicaCount=1
$ helm upgrade --install --namespace "demo" --create-namespace druid-minio minio/tenant \
--set tenant.pools[0].servers=1 \
--set tenant.pools[0].volumesPerServer=1 \
--set tenant.pools[0].size=1Gi \
--set tenant.certificate.requestAutoCert=false \
--set tenant.buckets[0].name="druid" \
--set tenant.pools[0].name="default"
Now we need to create a Secret named deep-storage-config. It contains the necessary connection information using which the druid database will connect to the deep storage.
apiVersion: v1
kind: Secret
metadata:
name: deep-storage-config
namespace: demo
stringData:
druid.storage.type: "s3"
druid.storage.bucket: "druid"
druid.storage.baseKey: "druid/segments"
druid.s3.accessKey: "minio"
druid.s3.secretKey: "minio123"
druid.s3.protocol: "http"
druid.s3.enablePathStyleAccess: "true"
druid.s3.endpoint.signingRegion: "us-east-1"
druid.s3.endpoint.url: "http://myminio-hl.demo.svc.cluster.local:9000/"
Let’s create the deep-storage-config Secret shown above:
$ kubectl create -f https://github.com/kubedb/docs/raw/v2024.11.18/docs/guides/druid/backup/application-level/examples/deep-storage-config.yaml
secret/deep-storage-config created
Use Custom Configuration
Say we want to change the default maximum number of tasks the MiddleManager can accept. Let’s create the middleManagers.properties file with our desire configurations.
middleManagers.properties:
druid.worker.capacity=5
and we also want to change the number of processing threads to have available for parallel processing of segments of the historicals nodes. Let’s create the historicals.properties file with our desire configurations.
historicals.properties:
druid.processing.numThreads=3
Let’s create a k8s secret containing the above configuration where the file name will be the key and the file-content as the value:
apiVersion: v1
kind: Secret
metadata:
name: configsecret
namespace: demo
stringData:
middleManagers.properties: |-
druid.worker.capacity=5
historicals.properties: |-
druid.processing.numThreads=3
$ kubectl apply -f https://github.com/kubedb/docs/raw/v2024.11.18/docs/guides/druid/configuration/config-file/yamls/config-secret.yaml
secret/config-secret created
To provide custom configuration for other nodes add values for the following
keyunderstringData:
- Use
common.runtime.propertiesfor common configurations- Use
coordinators.propertiesfor configurations of coordinators- Use
overlords.propertiesfor configurations of overlords- Use
brokers.propertiesfor configurations of brokers- Use
routers.propertiesfor configurations of routers
Now that the config secret is created, it needs to be mentioned in the Druid object’s yaml:
apiVersion: kubedb.com/v1alpha2
kind: Druid
metadata:
name: druid-with-config
namespace: demo
spec:
version: 28.0.1
configSecret:
name: config-secret
deepStorage:
type: s3
configSecret:
name: deep-storage-config
topology:
routers:
replicas: 1
deletionPolicy: WipeOut
Now, create the Druid object by the following command:
$ kubectl apply -f https://github.com/kubedb/docs/raw/v2024.11.18/docs/guides/druid/configuration/config-file/yamls/druid-with-monitoring.yaml
druid.kubedb.com/druid-with-config created
Now, wait for the Druid to become ready:
$ kubectl get dr -n demo -w
NAME TYPE VERSION STATUS AGE
druid-with-config kubedb.com/v1 3.6.1 Provisioning 5s
druid-with-config kubedb.com/v1 3.6.1 Provisioning 7s
.
.
druid-with-config kubedb.com/v1 3.6.1 Ready 2m
Verify Configuration
Lets exec into one of the druid middleManagers pod that we have created and check the configurations are applied or not:
Exec into the Druid middleManagers:
$ kubectl exec -it -n demo druid-with-config-middleManagers-0 -- bash
Defaulted container "druid" out of: druid, init-druid (init)
bash-5.1$
Now, execute the following commands to see the configurations:
bash-5.1$ cat conf/druid/cluster/data/middleManager/runtime.properties | grep druid.worker.capacity
druid.worker.capacity=5
Here, we can see that our given configuration is applied to the Druid cluster for all brokers.
Now, lets exec into one of the druid historicals pod that we have created and check the configurations are applied or not:
Exec into the Druid historicals:
$ kubectl exec -it -n demo druid-with-config-historicals-0 -- bash
Defaulted container "druid" out of: druid, init-druid (init)
bash-5.1$
Now, execute the following commands to see the metadata storage directory:
bash-5.1$ cat conf/druid/cluster/data/historical/runtime.properties | grep druid.processing.numThreads
druid.processing.numThreads=3
Here, we can see that our given configuration is applied to the historicals.
Verify Configuration Change from Druid UI
You can also see the configuration changes from the druid ui. For that, follow the following steps:
First port-forward the port 8888 to local machine:
$ kubectl port-forward -n demo svc/druid-with-config-routers 8888
Forwarding from 127.0.0.1:8888 -> 8888
Forwarding from [::1]:8888 -> 8888
Now hit the http://localhost:8888 from any browser, and you will be prompted to provide the credential of the druid database. By following the steps discussed below, you can get the credential generated by the KubeDB operator for your Druid database.
Connection information:
Username:
$ kubectl get secret -n demo druid-with-config-admin-cred -o jsonpath='{.data.username}' | base64 -d adminPassword:
$ kubectl get secret -n demo druid-with-config-admin-cred -o jsonpath='{.data.password}' | base64 -d LzJtVRX5E8MorFaf
After providing the credentials correctly, you should be able to access the web console like shown below.
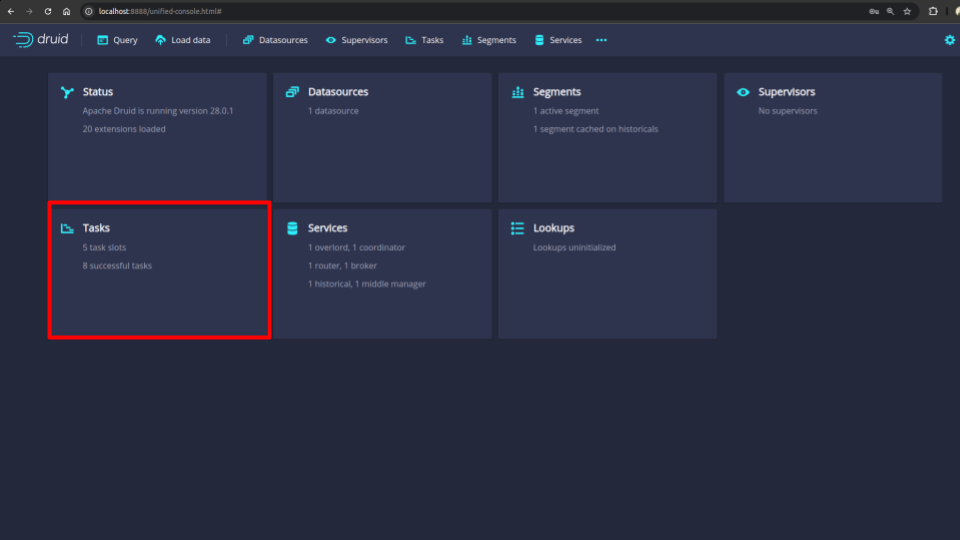
You can see that there are 5 task slots reflecting with our provided custom configuration of druid.worker.capacity=5.
Cleanup
To cleanup the Kubernetes resources created by this tutorial, run:
$ kubectl delete dr -n demo druid-dev
$ kubectl delete secret -n demo configsecret-combined
$ kubectl delete namespace demo
Next Steps
- Detail concepts of Druid object.
- Different Druid topology clustering modes here.
- Want to hack on KubeDB? Check our contribution guidelines.