



































You are looking at the documentation of a prior release. To read the documentation of the latest release, please
visit here.
New to KubeDB? Please start here.
Monitoring Apache Druid with KubeDB
KubeDB has native support for monitoring via Prometheus. You can use builtin Prometheus scraper or Prometheus operator to monitor KubeDB managed databases. This tutorial will show you how database monitoring works with KubeDB and how to configure Database crd to enable monitoring.
Overview
KubeDB uses Prometheus exporter images to export Prometheus metrics for respective databases. As KubeDB supports Druid versions in KRaft mode, and the officially recognized exporter image doesn’t expose metrics for them yet - KubeDB managed Druid instances use JMX Exporter instead. This exporter is intended to be run as a Java Agent inside Druid container, exposing a HTTP server and serving metrics of the local JVM. To Following diagram shows the logical flow of database monitoring with KubeDB.
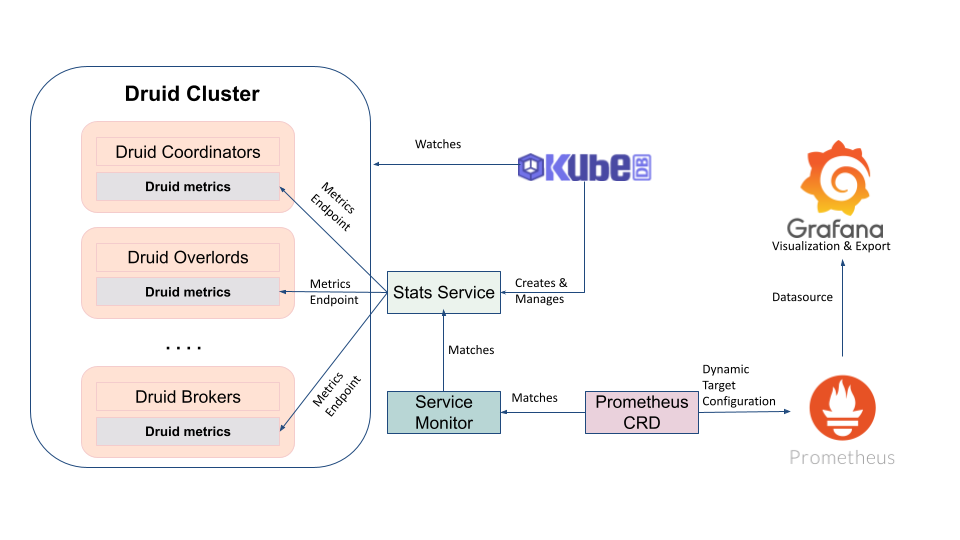
When a user creates a Druid crd with spec.monitor section configured, KubeDB operator provisions the respective Druid cluster while running the exporter as a Java agent inside the druid containers. It also creates a dedicated stats service with name {database-crd-name}-stats for monitoring. Prometheus server can scrape metrics using this stats service.
Configure Monitoring
In order to enable monitoring for a database, you have to configure spec.monitor section. KubeDB provides following options to configure spec.monitor section:
| Field | Type | Uses |
|---|---|---|
spec.monitor.agent | Required | Type of the monitoring agent that will be used to monitor this database. It can be prometheus.io/builtin or prometheus.io/operator. |
spec.monitor.prometheus.exporter.port | Optional | Port number where the exporter side car will serve metrics. |
spec.monitor.prometheus.exporter.args | Optional | Arguments to pass to the exporter sidecar. |
spec.monitor.prometheus.exporter.env | Optional | List of environment variables to set in the exporter sidecar container. |
spec.monitor.prometheus.exporter.resources | Optional | Resources required by exporter sidecar container. |
spec.monitor.prometheus.exporter.securityContext | Optional | Security options the exporter should run with. |
spec.monitor.prometheus.serviceMonitor.labels | Optional | Labels for ServiceMonitor crd. |
spec.monitor.prometheus.serviceMonitor.interval | Optional | Interval at which metrics should be scraped. |
Sample Configuration
A sample YAML for TLS secured Druid crd with spec.monitor section configured to enable monitoring with Prometheus operator is shown below.
apiVersion: kubedb.com/v1alpha2
kind: Druid
metadata:
name: druid-with-monitoring
namespace: demo
spec:
version: 28.0.1
deepStorage:
type: s3
configSecret:
name: deep-storage-config
topology:
routers:
replicas: 1
monitor:
agent: prometheus.io/operator
prometheus:
serviceMonitor:
labels:
release: prometheus
interval: 10s
deletionPolicy: WipeOut
Create External Dependency (Deep Storage)
Before proceeding further, we need to prepare deep storage, which is one of the external dependency of Druid and used for storing the segments. It is a storage mechanism that Apache Druid does not provide. Amazon S3, Google Cloud Storage, or Azure Blob Storage, S3-compatible storage (like Minio), or HDFS are generally convenient options for deep storage.
In this tutorial, we will run a minio-server as deep storage in our local kind cluster using minio-operator and create a bucket named druid in it, which the deployed druid database will use.
$ helm repo add minio https://operator.min.io/
$ helm repo update minio
$ helm upgrade --install --namespace "minio-operator" --create-namespace "minio-operator" minio/operator --set operator.replicaCount=1
$ helm upgrade --install --namespace "demo" --create-namespace druid-minio minio/tenant \
--set tenant.pools[0].servers=1 \
--set tenant.pools[0].volumesPerServer=1 \
--set tenant.pools[0].size=1Gi \
--set tenant.certificate.requestAutoCert=false \
--set tenant.buckets[0].name="druid" \
--set tenant.pools[0].name="default"
Now we need to create a Secret named deep-storage-config. It contains the necessary connection information using which the druid database will connect to the deep storage.
apiVersion: v1
kind: Secret
metadata:
name: deep-storage-config
namespace: demo
stringData:
druid.storage.type: "s3"
druid.storage.bucket: "druid"
druid.storage.baseKey: "druid/segments"
druid.s3.accessKey: "minio"
druid.s3.secretKey: "minio123"
druid.s3.protocol: "http"
druid.s3.enablePathStyleAccess: "true"
druid.s3.endpoint.signingRegion: "us-east-1"
druid.s3.endpoint.url: "http://myminio-hl.demo.svc.cluster.local:9000/"
Let’s create the deep-storage-config Secret shown above:
$ kubectl create -f https://github.com/kubedb/docs/raw/v2024.11.18/docs/guides/druid/monitoring/yamls/deep-storage-config.yaml
secret/deep-storage-config created
Let’s deploy the above druid example by the following command:
$ kubectl create -f https://github.com/kubedb/docs/raw/v2024.11.18/docs/guides/druid/monitoring/yamls/druid-with-monitoring.yaml
druid.kubedb.com/druid created
Here, we have specified that we are going to monitor this server using Prometheus operator through spec.monitor.agent: prometheus.io/operator. KubeDB will create a ServiceMonitor crd in databases namespace and this ServiceMonitor will have release: prometheus label.
Next Steps
- Learn how to use KubeDB to run a Apache Druid cluster here.
- Deploy dedicated topology cluster for Apache Druid
- Detail concepts of DruidVersion object.
- Want to hack on KubeDB? Check our contribution guidelines.