
































You are looking at the documentation of a prior release. To read the documentation of the latest release, please
visit here.
New to KubeDB? Please start here.
Horizontal Scale Druid Topology Cluster
This guide will show you how to use KubeDB Ops-manager operator to scale the Druid topology cluster.
Before You Begin
At first, you need to have a Kubernetes cluster, and the
kubectlcommand-line tool must be configured to communicate with your cluster. If you do not already have a cluster, you can create one by using kind.Install
KubeDBProvisioner and Ops-manager operator in your cluster following the steps here.You should be familiar with the following
KubeDBconcepts:
To keep everything isolated, we are going to use a separate namespace called demo throughout this tutorial.
$ kubectl create ns demo
namespace/demo created
Note: YAML files used in this tutorial are stored in docs/examples/druid directory of kubedb/docs repository.
Apply Horizontal Scaling on Druid Cluster
Here, we are going to deploy a Druid cluster using a supported version by KubeDB operator. Then we are going to apply horizontal scaling on it.
Prepare Druid Topology cluster
Now, we are going to deploy a Druid topology cluster with version 28.0.1.
Create External Dependency (Deep Storage)
Before proceeding further, we need to prepare deep storage, which is one of the external dependency of Druid and used for storing the segments. It is a storage mechanism that Apache Druid does not provide. Amazon S3, Google Cloud Storage, or Azure Blob Storage, S3-compatible storage (like Minio), or HDFS are generally convenient options for deep storage.
In this tutorial, we will run a minio-server as deep storage in our local kind cluster using minio-operator and create a bucket named druid in it, which the deployed druid database will use.
$ helm repo add minio https://operator.min.io/
$ helm repo update minio
$ helm upgrade --install --namespace "minio-operator" --create-namespace "minio-operator" minio/operator --set operator.replicaCount=1
$ helm upgrade --install --namespace "demo" --create-namespace druid-minio minio/tenant \
--set tenant.pools[0].servers=1 \
--set tenant.pools[0].volumesPerServer=1 \
--set tenant.pools[0].size=1Gi \
--set tenant.certificate.requestAutoCert=false \
--set tenant.buckets[0].name="druid" \
--set tenant.pools[0].name="default"
Now we need to create a Secret named deep-storage-config. It contains the necessary connection information using which the druid database will connect to the deep storage.
apiVersion: v1
kind: Secret
metadata:
name: deep-storage-config
namespace: demo
stringData:
druid.storage.type: "s3"
druid.storage.bucket: "druid"
druid.storage.baseKey: "druid/segments"
druid.s3.accessKey: "minio"
druid.s3.secretKey: "minio123"
druid.s3.protocol: "http"
druid.s3.enablePathStyleAccess: "true"
druid.s3.endpoint.signingRegion: "us-east-1"
druid.s3.endpoint.url: "http://myminio-hl.demo.svc.cluster.local:9000/"
Let’s create the deep-storage-config Secret shown above:
$ kubectl create -f https://github.com/kubedb/docs/raw/v2024.11.18/docs/guides/druid/scaling/horizontal-scaling/yamls/deep-storage-config.yaml
secret/deep-storage-config created
Deploy Druid topology cluster
In this section, we are going to deploy a Druid topology cluster. Then, in the next section we will scale the cluster using DruidOpsRequest CRD. Below is the YAML of the Druid CR that we are going to create,
apiVersion: kubedb.com/v1alpha2
kind: Druid
metadata:
name: druid-cluster
namespace: demo
spec:
version: 28.0.1
deepStorage:
type: s3
configSecret:
name: deep-storage-config
topology:
routers:
replicas: 1
deletionPolicy: Delete
Let’s create the Druid CR we have shown above,
$ kubectl create -f https://github.com/kubedb/docs/raw/v2024.11.18/docs/examples/druid/scaling/horizontal-scaling/yamls/druid-topology.yaml
druid.kubedb.com/druid-cluster created
Now, wait until druid-cluster has status Ready. i.e,
$ kubectl get dr -n demo -w
NAME TYPE VERSION STATUS AGE
druid-cluster kubedb.com/v1aplha2 28.0.1 Provisioning 0s
druid-cluster kubedb.com/v1aplha2 28.0.1 Provisioning 24s
.
.
druid-cluster kubedb.com/v1aplha2 28.0.1 Ready 92s
Let’s check the number of replicas has from druid object, number of pods the petset have,
Coordinators Replicas
$ kubectl get druid -n demo druid-cluster -o json | jq '.spec.topology.coordinators.replicas'
1
$ kubectl get petset -n demo druid-cluster-coordinators -o json | jq '.spec.replicas'
1
Historicals Replicas
$ kubectl get druid -n demo druid-cluster -o json | jq '.spec.topology.historicals.replicas'
1
$ kubectl get petset -n demo druid-cluster-historicals -o json | jq '.spec.replicas'
1
We can see from commands that the cluster has 1 replicas for both coordinators and historicals.
Check Replica Count from Druid UI
You can also see the replica count of each node from the druid ui. For that, follow the following steps:
First port-forward the port 8888 to local machine:
$ kubectl port-forward -n demo svc/druid-cluster-routers 8888
Forwarding from 127.0.0.1:8888 -> 8888
Forwarding from [::1]:8888 -> 8888
Now hit the http://localhost:8888 from any browser, and you will be prompted to provide the credential of the druid database. By following the steps discussed below, you can get the credential generated by the KubeDB operator for your Druid database.
Connection information:
Username:
$ kubectl get secret -n demo druid-cluster-admin-cred -o jsonpath='{.data.username}' | base64 -d adminPassword:
$ kubectl get secret -n demo druid-cluster-admin-cred -o jsonpath='{.data.password}' | base64 -d LzJtVRX5E8MorFaf
After providing the credentials correctly, you should be able to access the web console like shown below.
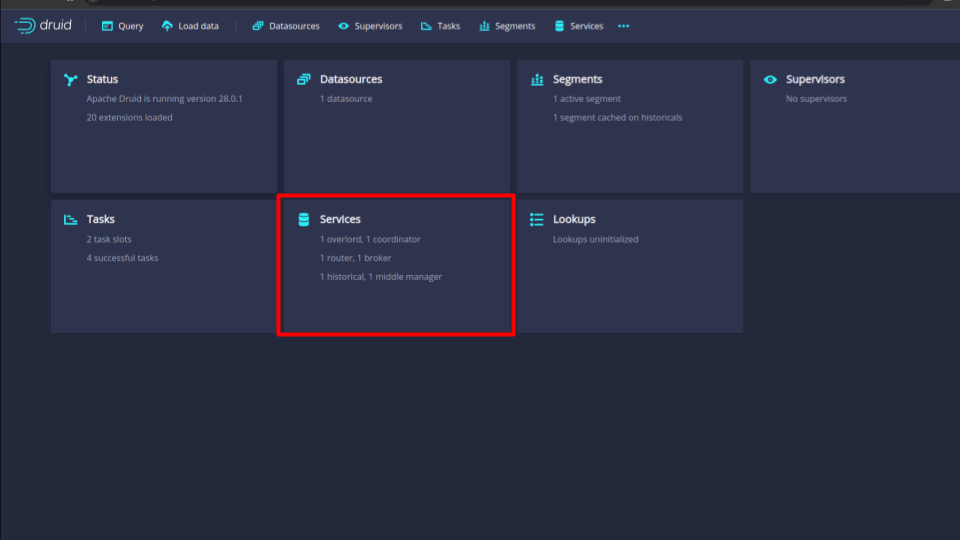
Here, we can see that there is 1 replica of each node including coordinators and historicals.
We are now ready to apply the DruidOpsRequest CR to scale this cluster.
Scale Up Replicas
Here, we are going to scale up the replicas of the topology cluster to meet the desired number of replicas after scaling.
Create DruidOpsRequest
In order to scale up the replicas of the topology cluster, we have to create a DruidOpsRequest CR with our desired replicas. Below is the YAML of the DruidOpsRequest CR that we are going to create,
apiVersion: ops.kubedb.com/v1alpha1
kind: DruidOpsRequest
metadata:
name: druid-hscale-up
namespace: demo
spec:
type: HorizontalScaling
databaseRef:
name: druid-cluster
horizontalScaling:
topology:
coordinators: 2
historicals: 2
Here,
spec.databaseRef.namespecifies that we are performing horizontal scaling operation ondruid-clustercluster.spec.typespecifies that we are performingHorizontalScalingon druid.spec.horizontalScaling.topology.coordinatorsspecifies the desired replicas after scaling for coordinators.spec.horizontalScaling.topology.historicalsspecifies the desired replicas after scaling for historicals.
Note: Similarly you can scale other druid nodes horizontally by specifying the following fields:
- For
overlordsusespec.horizontalScaling.topology.overlords.- For
brokersusespec.horizontalScaling.topology.brokers.- For
middleManagersusespec.horizontalScaling.topology.middleManagers.- For
routersusespec.horizontalScaling.topology.routers.
Let’s create the DruidOpsRequest CR we have shown above,
$ kubectl apply -f https://github.com/kubedb/docs/raw/v2024.11.18/docs/guides/druid/scaling/horizontal-scaling/yamls/druid-hscale-up.yaml
druidopsrequest.ops.kubedb.com/druid-hscale-up created
Verify Topology cluster replicas scaled up successfully
If everything goes well, KubeDB Ops-manager operator will update the replicas of Druid object and related PetSets and Pods.
Let’s wait for DruidOpsRequest to be Successful. Run the following command to watch DruidOpsRequest CR,
$ watch kubectl get druidopsrequest -n demo
NAME TYPE STATUS AGE
druid-hscale-up HorizontalScaling Successful 106s
We can see from the above output that the DruidOpsRequest has succeeded. If we describe the DruidOpsRequest we will get an overview of the steps that were followed to scale the cluster.
$ kubectl describe druidopsrequests -n demo druid-hscale-up
Name: druid-hscale-up
Namespace: demo
Labels: <none>
Annotations: <none>
API Version: ops.kubedb.com/v1alpha1
Kind: DruidOpsRequest
Metadata:
Creation Timestamp: 2024-10-21T11:32:51Z
Generation: 1
Managed Fields:
API Version: ops.kubedb.com/v1alpha1
Fields Type: FieldsV1
fieldsV1:
f:metadata:
f:annotations:
.:
f:kubectl.kubernetes.io/last-applied-configuration:
f:spec:
.:
f:apply:
f:databaseRef:
f:horizontalScaling:
.:
f:topology:
.:
f:coordinators:
f:historicals:
f:type:
Manager: kubectl-client-side-apply
Operation: Update
Time: 2024-10-21T11:32:51Z
API Version: ops.kubedb.com/v1alpha1
Fields Type: FieldsV1
fieldsV1:
f:status:
.:
f:conditions:
f:observedGeneration:
f:phase:
Manager: kubedb-ops-manager
Operation: Update
Subresource: status
Time: 2024-10-21T11:34:02Z
Resource Version: 91877
UID: 824356ca-eafc-4266-8af1-c372b27f6ce7
Spec:
Apply: IfReady
Database Ref:
Name: druid-cluster
Horizontal Scaling:
Topology:
Coordinators: 2
Historicals: 2
Type: HorizontalScaling
Status:
Conditions:
Last Transition Time: 2024-10-21T11:32:51Z
Message: Druid ops-request has started to horizontally scaling the nodes
Observed Generation: 1
Reason: HorizontalScaling
Status: True
Type: HorizontalScaling
Last Transition Time: 2024-10-21T11:33:17Z
Message: Successfully Scaled Up Broker
Observed Generation: 1
Reason: ScaleUpCoordinators
Status: True
Type: ScaleUpCoordinators
Last Transition Time: 2024-10-21T11:33:02Z
Message: patch pet setdruid-cluster-coordinators; ConditionStatus:True
Observed Generation: 1
Status: True
Type: PatchPetSetdruid-cluster-coordinators
Last Transition Time: 2024-10-21T11:33:57Z
Message: node in cluster; ConditionStatus:True
Observed Generation: 1
Status: True
Type: NodeInCluster
Last Transition Time: 2024-10-21T11:34:02Z
Message: Successfully Scaled Up Broker
Observed Generation: 1
Reason: ScaleUpHistoricals
Status: True
Type: ScaleUpHistoricals
Last Transition Time: 2024-10-21T11:33:22Z
Message: patch pet setdruid-cluster-historicals; ConditionStatus:True
Observed Generation: 1
Status: True
Type: PatchPetSetdruid-cluster-historicals
Last Transition Time: 2024-10-21T11:34:02Z
Message: Successfully completed horizontally scale druid cluster
Observed Generation: 1
Reason: Successful
Status: True
Type: Successful
Observed Generation: 1
Phase: Successful
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Starting 95s KubeDB Ops-manager Operator Start processing for DruidOpsRequest: demo/druid-hscale-up
Normal Starting 95s KubeDB Ops-manager Operator Pausing Druid databse: demo/druid-cluster
Normal Successful 95s KubeDB Ops-manager Operator Successfully paused Druid database: demo/druid-cluster for DruidOpsRequest: druid-hscale-up
Warning patch pet setdruid-cluster-coordinators; ConditionStatus:True 84s KubeDB Ops-manager Operator patch pet setdruid-cluster-coordinators; ConditionStatus:True
Warning node in cluster; ConditionStatus:False 76s KubeDB Ops-manager Operator node in cluster; ConditionStatus:False
Warning node in cluster; ConditionStatus:True 74s KubeDB Ops-manager Operator node in cluster; ConditionStatus:True
Normal ScaleUpCoordinators 69s KubeDB Ops-manager Operator Successfully Scaled Up Broker
Warning patch pet setdruid-cluster-historicals; ConditionStatus:True 64s KubeDB Ops-manager Operator patch pet setdruid-cluster-historicals; ConditionStatus:True
Warning node in cluster; ConditionStatus:False 56s KubeDB Ops-manager Operator node in cluster; ConditionStatus:False
Warning node in cluster; ConditionStatus:True 29s KubeDB Ops-manager Operator node in cluster; ConditionStatus:True
Normal ScaleUpHistoricals 24s KubeDB Ops-manager Operator Successfully Scaled Up Broker
Normal Starting 24s KubeDB Ops-manager Operator Resuming Druid database: demo/druid-cluster
Normal Successful 24s KubeDB Ops-manager Operator Successfully resumed Druid database: demo/druid-cluster for DruidOpsRequest: druid-hscale-up
Now, we are going to verify the number of replicas this cluster has from the Druid object, number of pods the petset have,
Coordinators Replicas
$ kubectl get druid -n demo druid-cluster -o json | jq '.spec.topology.coordinators.replicas'
2
$ kubectl get petset -n demo druid-cluster-coordinators -o json | jq '.spec.replicas'
2
Historicals Replicas
$ kubectl get druid -n demo druid-cluster -o json | jq '.spec.topology.historicals.replicas'
2
$ kubectl get petset -n demo druid-cluster-historicals -o json | jq '.spec.replicas'
2
Now, we are going to verify the number of replicas this cluster has from the Druid UI.
Verify Replica Count from Druid UI
Verify the scaled replica count of nodes from the druid ui. To access the UI follow the steps described in the first part of this guide. (Check Replica Count from Druid UI)
If you follow the steps properly, you should be able to see that the replica count of both coordinators and historicals has become 2. Also as the coordinators is serving as the overlords, the count of overlords has also become 2.
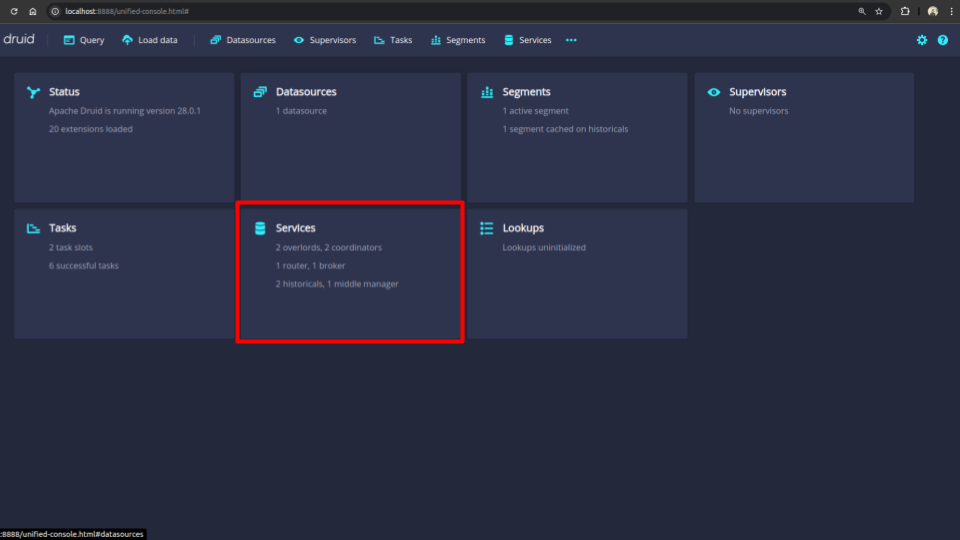
Scale Down Replicas
Here, we are going to scale down the replicas of the druid topology cluster to meet the desired number of replicas after scaling.
Create DruidOpsRequest
In order to scale down the replicas of the druid topology cluster, we have to create a DruidOpsRequest CR with our desired replicas. Below is the YAML of the DruidOpsRequest CR that we are going to create,
apiVersion: ops.kubedb.com/v1alpha1
kind: DruidOpsRequest
metadata:
name: druid-hscale-down
namespace: demo
spec:
type: HorizontalScaling
databaseRef:
name: druid-cluster
horizontalScaling:
topology:
coordinators: 1
historicals: 1
Here,
spec.databaseRef.namespecifies that we are performing horizontal scaling down operation ondruid-clustercluster.spec.typespecifies that we are performingHorizontalScalingon druid.spec.horizontalScaling.topology.coordinatorsspecifies the desired replicas after scaling for the coordinators nodes.spec.horizontalScaling.topology.historicalsspecifies the desired replicas after scaling for the historicals nodes.
Note: Similarly you can scale other druid nodes by specifying the following fields:
- For
overlordsusespec.horizontalScaling.topology.overlords.- For
brokersusespec.horizontalScaling.topology.brokers.- For
middleManagersusespec.horizontalScaling.topology.middleManagers.- For
routersusespec.horizontalScaling.topology.routers.
Let’s create the DruidOpsRequest CR we have shown above,
$ kubectl apply -f https://github.com/kubedb/docs/raw/v2024.11.18/docs/examples/druid/scaling/horizontal-scaling/druid-hscale-down-topology.yaml
druidopsrequest.ops.kubedb.com/druid-hscale-down created
Verify Topology cluster replicas scaled down successfully
If everything goes well, KubeDB Ops-manager operator will update the replicas of Druid object and related PetSets and Pods.
Let’s wait for DruidOpsRequest to be Successful. Run the following command to watch DruidOpsRequest CR,
$ watch kubectl get druidopsrequest -n demo
NAME TYPE STATUS AGE
druid-hscale-down HorizontalScaling Successful 2m32s
We can see from the above output that the DruidOpsRequest has succeeded. If we describe the DruidOpsRequest we will get an overview of the steps that were followed to scale the cluster.
$ kubectl get druidopsrequest -n demo druid-hscale-down -oyaml
apiVersion: ops.kubedb.com/v1alpha1
kind: DruidOpsRequest
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"ops.kubedb.com/v1alpha1","kind":"DruidOpsRequest","metadata":{"annotations":{},"name":"druid-hscale-down","namespace":"demo"},"spec":{"databaseRef":{"name":"druid-cluster"},"horizontalScaling":{"topology":{"coordinators":1,"historicals":1}},"type":"HorizontalScaling"}}
creationTimestamp: "2024-10-21T12:42:09Z"
generation: 1
name: druid-hscale-down
namespace: demo
resourceVersion: "99500"
uid: b3a81d07-be44-4adf-a8a7-36bb825f26a8
spec:
apply: IfReady
databaseRef:
name: druid-cluster
horizontalScaling:
topology:
coordinators: 1
historicals: 1
type: HorizontalScaling
status:
conditions:
- lastTransitionTime: "2024-10-21T12:42:09Z"
message: Druid ops-request has started to horizontally scaling the nodes
observedGeneration: 1
reason: HorizontalScaling
status: "True"
type: HorizontalScaling
- lastTransitionTime: "2024-10-21T12:42:33Z"
message: Successfully Scaled Down Broker
observedGeneration: 1
reason: ScaleDownCoordinators
status: "True"
type: ScaleDownCoordinators
- lastTransitionTime: "2024-10-21T12:42:23Z"
message: reassign partitions; ConditionStatus:True
observedGeneration: 1
status: "True"
type: ReassignPartitions
- lastTransitionTime: "2024-10-21T12:42:23Z"
message: is pet set patched; ConditionStatus:True
observedGeneration: 1
status: "True"
type: IsPetSetPatched
- lastTransitionTime: "2024-10-21T12:42:28Z"
message: get pod; ConditionStatus:True
observedGeneration: 1
status: "True"
type: GetPod
- lastTransitionTime: "2024-10-21T12:42:53Z"
message: Successfully Scaled Down Broker
observedGeneration: 1
reason: ScaleDownHistoricals
status: "True"
type: ScaleDownHistoricals
- lastTransitionTime: "2024-10-21T12:42:43Z"
message: delete pvc; ConditionStatus:True
observedGeneration: 1
status: "True"
type: DeletePvc
- lastTransitionTime: "2024-10-21T12:42:43Z"
message: get pvc; ConditionStatus:False
observedGeneration: 1
status: "False"
type: GetPvc
- lastTransitionTime: "2024-10-21T12:42:53Z"
message: Successfully completed horizontally scale druid cluster
observedGeneration: 1
reason: Successful
status: "True"
type: Successful
observedGeneration: 1
phase: Successful
Now, we are going to verify the number of replicas this cluster has from the Druid object, number of pods the petset have,
Coordinators Replicas
$ kubectl get druid -n demo druid-cluster -o json | jq '.spec.topology.coordinators.replicas'
1
$ kubectl get petset -n demo druid-cluster-coordinators -o json | jq '.spec.replicas'
1
Historicals Replicas
$ kubectl get druid -n demo druid-cluster -o json | jq '.spec.topology.historicals.replicas'
1
$ kubectl get petset -n demo druid-cluster-historicals -o json | jq '.spec.replicas'
1
Now, we are going to verify the number of replicas this cluster has from the Druid UI.
Verify Replica Count from Druid UI
Verify the scaled replica count of nodes from the druid ui. To access the UI follow the steps described in the first part of this guide. (Check Replica Count from Druid UI)
If you follow the steps properly, you should be able to see that the replica count of both coordinators and historicals has become 1. Also as the coordinators is serving as the overlords, the count of overlords has also become 1.
Cleaning Up
To clean up the Kubernetes resources created by this tutorial, run:
kubectl delete dr -n demo druid-cluster
kubectl delete druidopsrequest -n demo druid-hscale-up druid-hscale-down
kubectl delete ns demo
Next Steps
- Detail concepts of Druid object.
- Different Druid topology clustering modes here.
- Monitor your Druid with KubeDB using out-of-the-box Prometheus operator.
- Want to hack on KubeDB? Check our contribution guidelines.