



































You are looking at the documentation of a prior release. To read the documentation of the latest release, please
visit here.
Backup and restore Elasticsearch database deployed with KubeDB
Stash 0.9.0+ supports backup and restoration of Elasticsearch clusters. This guide will show you how you can backup and restore your KubeDB deployed Elasticsearch database using Stash.
Before You Begin
- At first, you need to have a Kubernetes cluster, and the
kubectlcommand-line tool must be configured to communicate with your cluster. - Install KubeDB in your cluster following the steps here.
- Install Stash in your cluster following the steps here.
- Install Stash
kubectlplugin following the steps here. - If you are not familiar with how Stash backup and restore Elasticsearch databases, please check the following guide here.
You have to be familiar with following custom resources:
To keep things isolated, we are going to use a separate namespace called demo throughout this tutorial. Create demo namespace if you haven’t created it yet.
$ kubectl create ns demo
namespace/demo created
Prepare Elasticsearch
In this section, we are going to deploy an Elasticsearch database using KubeDB. Then, we are going to insert some sample data into it.
Deploy Elasticsearch
At first, let’s deploy a sample Elasticsearch database. Below is the YAML of a sample Elasticsearch crd that we are going to create for this tutorial:
apiVersion: kubedb.com/v1
kind: Elasticsearch
metadata:
name: sample-es
namespace: demo
spec:
version: xpack-8.11.1
storageType: Durable
topology:
master:
suffix: master
replicas: 1
storage:
storageClassName: "standard"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
data:
suffix: data
replicas: 2
storage:
storageClassName: "standard"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
ingest:
suffix: client
replicas: 2
storage:
storageClassName: "standard"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
Let’s create the above Elasticsearch object,
$ kubectl apply -f https://github.com/kubedb/docs/raw/v2024.11.18/docs/guides/elasticsearch/backup/kubedb/examples/elasticsearch/sample_es.yaml
elasticsearch.kubedb.com/sample-es created
KubeDB will create the necessary resources to deploy the Elasticsearch database according to the above specification. Let’s wait until the database to be ready to use,
❯ kubectl get elasticsearch -n demo -w
NAME VERSION STATUS AGE
sample-es xpack-8.11.1 Provisioning 89s
sample-es xpack-8.11.1 Ready 5m26s
The database is in Ready state. It means the database is ready to accept connections.
Insert Sample Data
In this section, we are going to create few indexes in the deployed Elasticsearch. At first, we are going to port-forward the respective Service so that we can connect with the database from our local machine. Then, we are going to insert some data into the Elasticsearch.
Port-forward the Service
KubeDB will create few Services to connect with the database. Let’s see the Services created by KubeDB for our Elasticsearch,
❯ kubectl get service -n demo
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sample-es ClusterIP 10.108.129.195 <none> 9200/TCP 10m
sample-es-master ClusterIP None <none> 9300/TCP 10m
sample-es-pods ClusterIP None <none> 9200/TCP 10m
Here, we are going to use the sample-es Service to connect with the database. Now, let’s port-forward the sample-es Service. Run the following command into a separate terminal.
❯ kubectl port-forward -n demo service/sample-es 9200
Forwarding from 127.0.0.1:9200 -> 9200
Forwarding from [::1]:9200 -> 9200
Export the Credentials
KubeDB will create some Secrets for the database. Let’s check which Secrets have been created by KubeDB for our sample-es Elasticsearch.
❯ kubectl get secret -n demo | grep sample-es
sample-es-ca-cert kubernetes.io/tls 2 21m
sample-es-config Opaque 1 21m
sample-es-elastic-cred kubernetes.io/basic-auth 2 21m
sample-es-token-ctzn5 kubernetes.io/service-account-token 3 21m
sample-es-transport-cert kubernetes.io/tls 3 21m
Here, sample-es-elastic-cred contains the credentials require to connect with the database. Let’s export the credentials as environment variable to our current shell so that we can easily environment variables to connect with the database.
❯ export USER=$(kubectl get secrets -n demo sample-es-elastic-cred -o jsonpath='{.data.\username}' | base64 -d)
❯ export PASSWORD=$(kubectl get secrets -n demo sample-es-elastic-cred -o jsonpath='{.data.\password}' | base64 -d)
Insert data
Now, let’s create an index called products and insert some data into it.
# Elasticsearch will automatically create the index if it does not exist already.
❯ curl -XPOST --user "$USER:$PASSWORD" "http://localhost:9200/products/_doc?pretty" -H 'Content-Type: application/json' -d'
{
"name": "KubeDB",
"vendor": "AppsCode Inc.",
"description": "Database Operator for Kubernetes"
}
'
# Let's insert another data into the "products" index.
❯ curl -XPOST --user "$USER:$PASSWORD" "http://localhost:9200/products/_doc?pretty" -H 'Content-Type: application/json' -d'
{
"name": "Stash",
"vendor": "AppsCode Inc.",
"description": "Backup tool for Kubernetes workloads"
}
'
Let’s create another index called companies and insert some data into it.
❯ curl -XPOST --user "$USER:$PASSWORD" "http://localhost:9200/companies/_doc?pretty" -H 'Content-Type: application/json' -d'
{
"name": "AppsCode Inc.",
"mission": "Accelerate the transition to Containers by building a Kubernetes-native Data Platform",
"products": ["KubeDB", "Stash", "KubeVault", "Kubeform", "ByteBuilders"]
}
'
Now, let’s verify that the indexes have been created successfully.
❯ curl -XGET --user "$USER:$PASSWORD" "http://localhost:9200/_cat/indices?v&s=index&pretty"
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open companies qs52L4xrShay14NPUExDNw 1 1 1 0 11.5kb 5.7kb
green open products 6aCd7y_kQf26sYG3QdY0ow 1 1 2 0 20.7kb 10.3kb
Also, let’s verify the data in the indexes:
# Verify the data in the "product" index.
❯ curl -XGET --user "$USER:$PASSWORD" "http://localhost:9200/products/_search?pretty"
{
"took" : 354,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "products",
"_type" : "_doc",
"_id" : "3GyXa3cB55U52E6TvL8f",
"_score" : 1.0,
"_source" : {
"name" : "KubeDB",
"vendor" : "AppsCode Inc.",
"description" : "Database Operator for Kubernetes"
}
},
{
"_index" : "products",
"_type" : "_doc",
"_id" : "3WyYa3cB55U52E6Tc7_G",
"_score" : 1.0,
"_source" : {
"name" : "Stash",
"vendor" : "AppsCode Inc.",
"description" : "Backup tool for Kubernetes workloads"
}
}
]
}
}
# Verify data in the "companies" index.
❯ curl -XGET --user "$USER:$PASSWORD" "http://localhost:9200/companies/_search?pretty"
{
"took" : 172,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "companies",
"_type" : "_doc",
"_id" : "3myya3cB55U52E6TE78a",
"_score" : 1.0,
"_source" : {
"name" : "AppsCode Inc.",
"mission" : "Accelerate the transition to Containers by building a Kubernetes-native Data Platform",
"products" : [
"KubeDB",
"Stash",
"KubeVault",
"Kubeform",
"ByteBuilders"
]
}
}
]
}
}
We now have sample data in our database. In the next section, we are going to prepare the necessary resources to backup these sample data.
Prepare for Backup
In this section, we are going to prepare our cluster for backup.
Verify AppBinding
KubeDB will create an AppBinding object with the same name as the database object which contains the necessary information requires to connect with the database.
Let’s verify that the AppBinding object has been created for our sample-es Elasticsearch,
❯ kubectl get appbindings.appcatalog.appscode.com -n demo sample-es
NAME TYPE VERSION AGE
sample-es kubedb.com/elasticsearch 7.9.1 2d
Now, if you check the YAML of the AppBinding, you will see that it contains the service and secret information that are necessary to connect with the database.
❯ kubectl get appbindings.appcatalog.appscode.com -n demo sample-es -o yaml
apiVersion: appcatalog.appscode.com/v1alpha1
kind: AppBinding
metadata:
name: sample-es
namespace: demo
...
spec:
clientConfig:
service:
name: sample-es
port: 9200
scheme: http
secret:
name: sample-es-elastic-cred
parameters:
apiVersion: appcatalog.appscode.com/v1alpha1
kind: StashAddon
stash:
addon:
backupTask:
name: elasticsearch-backup-7.3.2
restoreTask:
name: elasticsearch-restore-7.3.2
type: kubedb.com/elasticsearch
version: 7.9.1
Here,
spec.parameters.stashsection specifies the Stash Addon that will be used to backup and restore this Elasticsearch.
Verify Stash Elasticsearch Addons Installed
When you install the Stash, it automatically installs all the official database addons. Verify that it has installed the Elasticsearch addons using the following command.
❯ kubectl get tasks.stash.appscode.com | grep elasticsearch
elasticsearch-backup-5.6.4 3d2h
elasticsearch-backup-6.2.4 3d2h
elasticsearch-backup-6.3.0 3d2h
elasticsearch-backup-6.4.0 3d2h
elasticsearch-backup-6.5.3 3d2h
elasticsearch-backup-6.8.0 3d2h
elasticsearch-backup-7.2.0 3d2h
elasticsearch-backup-7.3.2 3d2h
elasticsearch-restore-5.6.4 3d2h
elasticsearch-restore-6.2.4 3d2h
elasticsearch-restore-6.3.0 3d2h
elasticsearch-restore-6.4.0 3d2h
elasticsearch-restore-6.5.3 3d2h
elasticsearch-restore-6.8.0 3d2h
elasticsearch-restore-7.2.0 3d2h
elasticsearch-restore-7.3.2 3d2h
Prepare Backend
We are going to store our backed up data into a GCS bucket. So, we need to create a Secret with GCS credentials and a Repository object with the bucket information. If you want to use a different backend, please read the respective backend configuration doc from here.
Create Storage Secret
At first, let’s create a Secret called gcs-secret with access credentials to our desired GCS bucket,
$ echo -n 'changeit' > RESTIC_PASSWORD
$ echo -n '<your-project-id>' > GOOGLE_PROJECT_ID
$ cat downloaded-sa-key.json > GOOGLE_SERVICE_ACCOUNT_JSON_KEY
$ kubectl create secret generic -n demo gcs-secret \
--from-file=./RESTIC_PASSWORD \
--from-file=./GOOGLE_PROJECT_ID \
--from-file=./GOOGLE_SERVICE_ACCOUNT_JSON_KEY
secret/gcs-secret created
Create Repository
Now, crete a Repository object with the information of your desired bucket. Below is the YAML of Repository object we are going to create,
apiVersion: stash.appscode.com/v1alpha1
kind: Repository
metadata:
name: gcs-repo
namespace: demo
spec:
backend:
gcs:
bucket: stash-testing
prefix: /demo/sample-es
storageSecretName: gcs-secret
Let’s create the Repository we have shown above,
$ kubectl create -f https://github.com/kubedb/docs/raw/v2024.11.18/docs/guides/elasticsearch/backup/kubedb/examples/backup/repository.yaml
repository.stash.appscode.com/gcs-repo created
Now, we are ready to back up our database into our desired backend.
Backup
To schedule a backup, we have to create a BackupConfiguration object targeting the respective AppBinding of our desired database. Then, Stash will create a CronJob to periodically trigger a backup of the database.
Create BackupConfiguration
Below is the YAML for BackupConfiguration object we care going to use to backup the sample-es database we have deployed earlier,
apiVersion: stash.appscode.com/v1beta1
kind: BackupConfiguration
metadata:
name: sample-es-backup
namespace: demo
spec:
schedule: "*/5 * * * *"
repository:
name: gcs-repo
target:
ref:
apiVersion: appcatalog.appscode.com/v1alpha1
kind: AppBinding
name: sample-es
interimVolumeTemplate:
metadata:
name: sample-es-backup-tmp-storage
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "standard"
resources:
requests:
storage: 1Gi
retentionPolicy:
name: keep-last-5
keepLast: 5
prune: true
Here,
.spec.schedulespecifies that we want to backup the database every 5th minutes..spec.target.refrefers to theAppBindingobject that holds the connection information of our targeted database.spec.interimVolumeTemplatespecifies a PVC template that will be used by Stash to hold the dumped data temporarily before uploading it into the cloud bucket.
Let’s create the BackupConfiguration object we have shown above,
$ kubectl create -f https://github.com/kubedb/docs/raw/v2024.11.18/docs/guides/elasticsearch/backup/kubedb/examples/backup/backupconfiguration.yaml
backupconfiguration.stash.appscode.com/sample-es-backup created
Verify Backup Setup Successful
If everything goes well, the phase of the BackupConfiguration should be Ready. The Ready phase indicates that the backup setup is successful. Let’s verify the Phase of the BackupConfiguration,
$ kubectl get backupconfiguration -n demo
NAME TASK SCHEDULE PAUSED PHASE AGE
sample-es-backup elasticsearch-backup-7.3.2 */5 * * * * Ready 11s
Verify CronJob
Stash will create a CronJob with the schedule specified in the spec.schedule field of BackupConfiguration object.
Verify that the CronJob has been created using the following command,
❯ kubectl get cronjob -n demo
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
stash-backup-sample-es-backup */5 * * * * False 0 <none> 9s
Wait for BackupSession
The stash-backup-sample-es-backup CronJob will trigger a backup on each scheduled slot by creating a BackupSession object.
Now, wait for a schedule to appear. Run the following command to watch for a BackupSession object,
❯ kubectl get backupsessions.stash.appscode.com -n demo -w
NAME INVOKER-TYPE INVOKER-NAME PHASE AGE
sample-es-backup-1612440003 BackupConfiguration sample-es-backup 0s
sample-es-backup-1612440003 BackupConfiguration sample-es-backup Running 0s
sample-es-backup-1612440003 BackupConfiguration sample-es-backup Succeeded 54s
Here, the phase Succeeded means that the backup process has been completed successfully.
Verify Backup
Now, we are going to verify whether the backed up data is present in the backend or not. Once a backup is completed, Stash will update the respective Repository object to reflect the backup completion. Check that the repository gcs-repo has been updated by the following command,
❯ kubectl get repository -n demo gcs-repo
NAME INTEGRITY SIZE SNAPSHOT-COUNT LAST-SUCCESSFUL-BACKUP AGE
gcs-repo true 3.801 KiB 1 64s 3m46s
Now, if we navigate to the GCS bucket, we will see the backed up data has been stored in demo/sample-es directory as specified by the .spec.backend.gcs.prefix field of the Repository object.
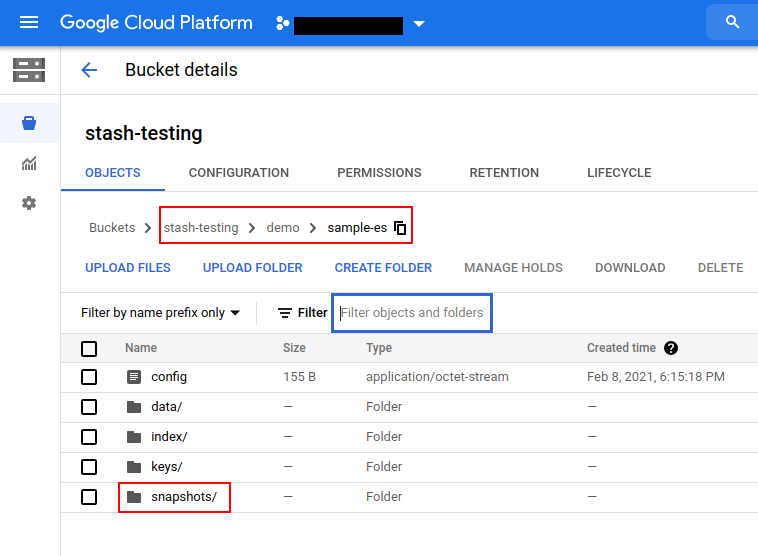
Note: Stash keeps all the backed up data encrypted. So, data in the backend will not make any sense until they are decrypted.
Restore
If you have followed the previous sections properly, you should have a successful backup of your Elasticsearch database. Now, we are going to show how you can restore the database from the backed up data.
Restore into the same Elasticsearch
You can restore your data into the same database you have backed up from or into a different database in the same cluster or a different cluster. In this section, we are going to show you how to restore in the same database which may be necessary when you have accidentally deleted any data from the running database.
Temporarily pause backup
At first, let’s stop taking any further backup of the database so that no backup runs after we delete the sample data. We are going to pause the BackupConfiguration object. Stash will stop taking any further backup when the BackupConfiguration is paused.
Let’s pause the sample-es-backup BackupConfiguration,
❯ kubectl patch backupconfiguration -n demo sample-es-backup --type="merge" --patch='{"spec": {"paused": true}}'
backupconfiguration.stash.appscode.com/sample-es-backup patched
Or you can use the Stash kubectl plugin to pause the BackupConfiguration,
❯ kubectl stash pause backup -n demo --backupconfig=sample-es-backup
BackupConfiguration demo/sample-es-backup has been paused successfully.
Verify that the BackupConfiguration has been paused,
❯ kubectl get backupconfiguration -n demo sample-es-backup
NAME TASK SCHEDULE PAUSED PHASE AGE
sample-es-backup elasticsearch-backup-7.3.2 */5 * * * * true Ready 12m
Notice the PAUSED column. Value true for this field means that the BackupConfiguration has been paused.
Stash will also suspend the respective CronJob.
❯ kubectl get cronjob -n demo
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
stash-backup-sample-es-backup */5 * * * * True 0 5m19s 12m
Simulate Disaster
Now, let’s simulate an accidental deletion scenario. Here, we are going to delete the products and companies indexes that we had created earlier.
# Delete "products" index
❯ curl -XDELETE --user "$USER:$PASSWORD" "http://localhost:9200/products?pretty"
{
"acknowledged" : true
}
# Delete "companies" index
❯ curl -XDELETE --user "$USER:$PASSWORD" "http://localhost:9200/companies?pretty"
{
"acknowledged" : true
}
Now, let’s verify that the indexes have been deleted from the database,
❯ curl -XGET --user "$USER:$PASSWORD" "http://localhost:9200/_cat/indices?v&s=index&pretty"
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
So, we can see our sample-es database does not have any indexes. In the next section, we are going to restore the deleted indexes from backed up data.
Create RestoreSession
To restore the database, you have to create a RestoreSession object pointing to the AppBinding of the targeted database.
Here, is the YAML of the RestoreSession object that we are going to use for restoring our sample-es database.
apiVersion: stash.appscode.com/v1beta1
kind: RestoreSession
metadata:
name: sample-es-restore
namespace: demo
spec:
repository:
name: gcs-repo
target:
ref:
apiVersion: appcatalog.appscode.com/v1alpha1
kind: AppBinding
name: sample-es
interimVolumeTemplate:
metadata:
name: sample-es-restore-tmp-storage
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "standard"
resources:
requests:
storage: 1Gi
rules:
- snapshots: [latest]
Here,
.spec.repository.namespecifies theRepositoryobject that holds the backend information where our backed up data has been stored..spec.target.refrefers to the respectiveAppBindingof thesample-esdatabase.spec.interimVolumeTemplatespecifies a PVC template that will be used by Stash to hold the restored data temporarily before injecting it into the database..spec.rulesspecifies that we are restoring data from the latest backup snapshot of the database.
Let’s create the RestoreSession object object we have shown above,
❯ kubectl apply -f https://github.com/kubedb/docs/raw/v2024.11.18/docs/guides/elasticsearch/backup/kubedb/examples/restore/restoresession.yaml
restoresession.stash.appscode.com/sample-es-restore created
Once, you have created the RestoreSession object, Stash will create a restore Job. Run the following command to watch the phase of the RestoreSession object,
❯ kubectl get restoresession -n demo -w
NAME REPOSITORY PHASE AGE
sample-es-restore gcs-repo Running 8s
sample-es-restore gcs-repo Running 24s
sample-es-restore gcs-repo Succeeded 24s
sample-es-restore gcs-repo Succeeded 25s
The Succeeded phase means that the restore process has been completed successfully.
Verify Restored Data
Now, it’s time to verify whether the actual data has been restored or not. At first, let’s verify that whether the indexes have been restored or not:
❯ curl -XGET --user "$USER:$PASSWORD" "http://localhost:9200/_cat/indices?v&s=index&pretty"
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open companies 7UgxlL4wST6ZIAImxRVvzw 1 1 1 0 11.4kb 5.7kb
green open products vb19PIneSL2zMTPvNEgm-w 1 1 2 0 10.8kb 5.4kb
So, we can see the indexes have been restored. Now, let’s verify the data of these indexes,
# Verify the data of the "products" index
❯ curl -XGET --user "$USER:$PASSWORD" "http://localhost:9200/products/_search?pretty"
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "products",
"_type" : "_doc",
"_id" : "vKDVgXcBa1PZYKwIDBjy",
"_score" : 1.0,
"_source" : {
"name" : "Stash",
"vendor" : "AppsCode Inc.",
"description" : "Backup tool for Kubernetes workloads"
}
},
{
"_index" : "products",
"_type" : "_doc",
"_id" : "u6DUgXcBa1PZYKwI5xic",
"_score" : 1.0,
"_source" : {
"name" : "KubeDB",
"vendor" : "AppsCode Inc.",
"description" : "Database Operator for Kubernetes"
}
}
]
}
}
# Verify the data of "companies" index
❯ curl -XGET --user "$USER:$PASSWORD" "http://localhost:9200/companies/_search?pretty"
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "companies",
"_type" : "_doc",
"_id" : "vaDVgXcBa1PZYKwIMxhm",
"_score" : 1.0,
"_source" : {
"name" : "AppsCode Inc.",
"mission" : "Accelerate the transition to Containers by building a Kubernetes-native Data Platform",
"products" : [
"KubeDB",
"Stash",
"KubeVault",
"Kubeform",
"ByteBuilders"
]
}
}
]
}
}
So, we can see that the data has been restored as well.
Resume Backup
Since our data has been restored successfully we can now resume our usual backup process. Resume the BackupConfiguration using following command,
❯ kubectl patch backupconfiguration -n demo sample-es-backup --type="merge" --patch='{"spec": {"paused": false}}'
backupconfiguration.stash.appscode.com/sample-es-backup patched
Or you can use Stash kubectl plugin to resume the BackupConfiguration,
❯ kubectl stash resume -n demo --backupconfig=sample-es-backup
BackupConfiguration demo/sample-es-backup has been resumed successfully.
Verify that the BackupConfiguration has been resumed,
❯ kubectl get backupconfiguration -n demo sample-es-backup
NAME TASK SCHEDULE PAUSED PHASE AGE
sample-es-backup elasticsearch-backup-7.3.2 */5 * * * * false Ready 30m
Here, false in the PAUSED column means the backup has been resume successfully. The CronJob also should be resumed now.
❯ kubectl get cronjob -n demo
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
stash-backup-sample-es-backup */5 * * * * False 0 2m50s 30m
Here, False in the SUSPEND column means the CronJob is no longer suspended and will trigger in the next schedule.
Restore into a different Elasticsearch
Now, we are going to restore the backed up data into a different Elasticsearch of a different namespace. This time, we are going to use opendistro variant for Elasticsearch to demonstrate migration between the variants. You can use the same variant of Elasticsearch if you are not considering to migrate from your current variant.
We are going to restore the data into an Elasticsearch in restored namespace. If you already don’t have the namespace, let’s create it first.
❯ kubectl create ns restored
namespace/restored created
Copy Repository and backend Secret into the new namespace
Now, let’s copy the gcs-repo Repository into our new namespace using the stash kubectl plugin,
❯ kubectl stash cp repository gcs-repo -n demo --to-namespace=restored
I0208 19:51:43.950560 666626 copy_repository.go:58] Repository demo/gcs-repo uses Storage Secret demo/gcs-secret.
I0208 19:51:43.952899 666626 copy_secret.go:60] Copying Storage Secret demo to restored namespace
I0208 19:51:43.957204 666626 copy_secret.go:73] Secret demo/gcs-secret has been copied to restored namespace successfully.
I0208 19:51:43.967768 666626 copy_repository.go:75] Repository demo/gcs-repo has been copied to restored namespace successfully.
The above command will copy the gcs-repo Repository as well as the respective backend secret gcs-secret.
Let’s verify that the Repository has been copied into restored namespace,
❯ kubectl get repository -n restored
NAME INTEGRITY SIZE SNAPSHOT-COUNT LAST-SUCCESSFUL-BACKUP AGE
gcs-repo 2m9s
The command does not copy the status of the
Repository. As a result, you will see theINTEGRITY,SIZE,SNAPSHOT-COUNT, andLAST-SUCCESSFUL-BACKUPfields are empty. Nothing to panic about here. Your actual data exist safely in the cloud bucket. TheRepositoryjust contains the connection information to that bucket.
Now, let’s verify that the backend secret has been copied as well,
❯ kubectl get secret -n restored
NAME TYPE DATA AGE
default-token-rd2v5 kubernetes.io/service-account-token 3 15m
gcs-secret Opaque 3 8m36s
As you can see, the backend secret gcs-secret also has been copied to restored namespace.
Deploy new Elasticsearch
Now, we are going to deploy an Elasticsearch into restored namespace. We are going to initialize this database from the backed up data of first Elasticsearch.
Here, is the YAML of the Elasticsearch object that we are going to create,
apiVersion: kubedb.com/v1
kind: Elasticsearch
metadata:
name: init-sample
namespace: restored
spec:
version: opensearch-2.8.0
storageType: Durable
init:
waitForInitialRestore: true
topology:
master:
suffix: master
replicas: 1
storage:
storageClassName: "standard"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
data:
suffix: data
replicas: 2
storage:
storageClassName: "standard"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
ingest:
suffix: client
replicas: 2
storage:
storageClassName: "standard"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
Notice that this time, we are using 1.9.0-opendistro variant for Elasticsearch. Also, notice that we have added an init section in the spec. Here, waitForInitialRestore: true tells KubeDB to wait for the first restore to complete before marking this database as ready to use.
Let’s deploy the above Elasticsearch,
❯ kubectl apply -f https://github.com/kubedb/docs/raw/v2024.11.18/docs/guides/elasticsearch/backup/kubedb/examples/elasticsearch/init_sample.yaml
elasticsearch.kubedb.com/init-sample created
Now, wait for the KubeDB to create all the nodes for this Elasticsearch. This time, Elasticsearch will get stuck in the Provisioning state because we haven’t completed the first restore yet.
You can check the condition of the Elasticsearch to verify whether we are ready to restore the database.
❯ kubectl get elasticsearch -n restored init-sample -o jsonpath='{.status.conditions}' | jq
[
{
"lastTransitionTime": "2021-02-08T14:13:22Z",
"message": "The KubeDB operator has started the provisioning of Elasticsearch: restored/init-sample",
"reason": "DatabaseProvisioningStartedSuccessfully",
"status": "True",
"type": "ProvisioningStarted"
},
{
"lastTransitionTime": "2021-02-08T14:18:15Z",
"message": "All desired replicas are ready.",
"reason": "AllReplicasReady",
"status": "True",
"type": "ReplicaReady"
},
{
"lastTransitionTime": "2021-02-08T14:19:22Z",
"message": "The Elasticsearch: restored/init-sample is accepting client requests.",
"observedGeneration": 3,
"reason": "DatabaseAcceptingConnectionRequest",
"status": "True",
"type": "AcceptingConnection"
},
{
"lastTransitionTime": "2021-02-08T14:19:33Z",
"message": "The Elasticsearch: restored/init-sample is ready.",
"observedGeneration": 3,
"reason": "ReadinessCheckSucceeded",
"status": "True",
"type": "Ready"
}
]
Here, check the last two conditions. We can see that the database has passed the readiness check from Ready conditions and it is accepting connections from AcceptingConnection condition. So, we are good to start restoring into this database.
KubeDB has created an AppBinding for this database. Let’s verify that the AppBinding has been created,
❯ kubectl get appbindings.appcatalog.appscode.com -n restored
NAME TYPE VERSION AGE
init-sample kubedb.com/elasticsearch 7.8.0 21m
We are going to create a RestoreSession targeting this AppBinding to restore into this database.
Create RestoreSession for new Elasticsearch
Now, we have to create a RestoreSession object targeting the AppBinding of our init-sample database. Here, is the YAML of the RestoreSession that we are going to create,
apiVersion: stash.appscode.com/v1beta1
kind: RestoreSession
metadata:
name: init-sample-restore
namespace: restored
spec:
repository:
name: gcs-repo
target:
ref:
apiVersion: appcatalog.appscode.com/v1alpha1
kind: AppBinding
name: init-sample
interimVolumeTemplate:
metadata:
name: init-sample-restore-tmp-storage
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "standard"
resources:
requests:
storage: 1Gi
rules:
- snapshots: [latest]
Let’s create the above RestoreSession,
❯ kubectl apply -f https://github.com/kubedb/docs/raw/v2024.11.18/docs/guides/elasticsearch/backup/kubedb/examples/restore/init_sample_restore.yaml
restoresession.stash.appscode.com/init-sample-restore created
Now, wait for the restore process to complete,
❯ kubectl get restoresession -n restored -w
NAME REPOSITORY PHASE AGE
init-sample-restore gcs-repo Running 4s
init-sample-restore gcs-repo Running 21s
init-sample-restore gcs-repo Succeeded 21s
init-sample-restore gcs-repo Succeeded 21s
Verify Restored Data in new Elasticsearch
Now, we are going to verify whether the data has been restored or not. At first let’s port-forward the respective Service for this Elasticsearch,
❯ kubectl get service -n restored
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
init-sample ClusterIP 10.109.51.219 <none> 9200/TCP 54m
init-sample-master ClusterIP None <none> 9300/TCP 54m
init-sample-pods ClusterIP None <none> 9200/TCP 54m
❯ kubectl port-forward -n restored service/init-sample 9200
Forwarding from 127.0.0.1:9200 -> 9200
Forwarding from [::1]:9200 -> 9200
Now, let’s export the credentials of this Elasticsearch,
❯ kubectl get secret -n restored | grep init-sample
init-sample-admin-cred kubernetes.io/basic-auth 2 55m
init-sample-ca-cert kubernetes.io/tls 2 55m
init-sample-config Opaque 3 55m
init-sample-kibanaro-cred kubernetes.io/basic-auth 2 55m
init-sample-kibanaserver-cred kubernetes.io/basic-auth 2 55m
init-sample-logstash-cred kubernetes.io/basic-auth 2 55m
init-sample-readall-cred kubernetes.io/basic-auth 2 55m
init-sample-snapshotrestore-cred kubernetes.io/basic-auth 2 55m
init-sample-token-xgnrx kubernetes.io/service-account-token 3 55m
init-sample-transport-cert kubernetes.io/tls 3 55m
stash-restore-init-sample-restore-0-token-vscdt kubernetes.io/service-account-token 3 4m40s
Here, we are going to use the init-sample-admin-cred for connecting with the database. Let’s export the username and password keys.
❯ export USER=$(kubectl get secrets -n restored init-sample-admin-cred -o jsonpath='{.data.\username}' | base64 -d)
❯ export PASSWORD=$(kubectl get secrets -n restored init-sample-admin-cred -o jsonpath='{.data.\password}' | base64 -d)
Now, let’s verify whether the indexes have been restored or not.
❯ curl -XGET --user "$USER:$PASSWORD" "http://localhost:9200/_cat/indices?v&s=index&pretty"
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .opendistro_security _v-_YiJUReylNbUaIEXN8A 1 1 7 0 57.1kb 37.1kb
green open companies XfSvxePuS7-lNq-gcd-bxg 1 1 1 0 11.1kb 5.5kb
green open products pZYHzOp_TWK9bLaEU-uj8Q 1 1 2 0 10.5kb 5.2kb
So, we can see that our indexes have been restored successfully. Now, let’s verify the data of these indexes.
# Verify data of "products" index
❯ curl -XGET --user "$USER:$PASSWORD" "http://localhost:9200/products/_search?pretty"
{
"took" : 634,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "products",
"_type" : "_doc",
"_id" : "u6DUgXcBa1PZYKwI5xic",
"_score" : 1.0,
"_source" : {
"name" : "KubeDB",
"vendor" : "AppsCode Inc.",
"description" : "Database Operator for Kubernetes"
}
},
{
"_index" : "products",
"_type" : "_doc",
"_id" : "vKDVgXcBa1PZYKwIDBjy",
"_score" : 1.0,
"_source" : {
"name" : "Stash",
"vendor" : "AppsCode Inc.",
"description" : "Backup tool for Kubernetes workloads"
}
}
]
}
}
# Verify data of "companies" index
❯ curl -XGET --user "$USER:$PASSWORD" "http://localhost:9200/companies/_search?pretty"
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "companies",
"_type" : "_doc",
"_id" : "vaDVgXcBa1PZYKwIMxhm",
"_score" : 1.0,
"_source" : {
"name" : "AppsCode Inc.",
"mission" : "Accelerate the transition to Containers by building a Kubernetes-native Data Platform",
"products" : [
"KubeDB",
"Stash",
"KubeVault",
"Kubeform",
"ByteBuilders"
]
}
}
]
}
}
So, we can see that the data of these indexes data has been restored too.
Restore into a different cluster
If you want to restore into a different cluster, you have to install KubeDB and Stash in the desired cluster. Then, you have to install Stash Elasticsearch addon in that cluster too. Then, you have to deploy the target database there. Once, the database is ready to accept connections, create the Repository, backend Secret, in the same namespace as the database of your desired cluster. Finally, create the RestoreSession object in the desired cluster pointing to the AppBinding of the targeted database of that cluster.
Cleanup
To cleanup the Kubernetes resources created by this tutorial, run:
# delete all reasources from "demo" namespace
kubectl delete -n demo backupconfiguration sample-es-backup
kubectl delete -n demo restoresession sample-es-restore
kubectl delete -n demo repository gcs-repo
kubectl delete -n demo secret gcs-repo
kubectl delete -n demo secret gcs-secret
kubectl delete -n demo elasticsearch sample-es
# delete all reasources from "restored" namespace
kubectl delete -n restored restoresession init-sample-restore
kubectl delete -n restored repository gcs-repo
kubectl delete -n restored secret gcs-secret
kubectl delete -n restored elasticsearch init-sample