



































You are looking at the documentation of a prior release. To read the documentation of the latest release, please
visit here.
Druid Backup and Restore for Cross Namespace Dependencies using KubeStash
KubeStash offers backup and restore functionality for Druid with dependencies in different namespaces.
This guide will give you how you can take Application Level Backup and restore your Druid databases, with dependencies in different namespaces in using Kubestash. In application level backup both manifest and logical data backups of any Druid database are captured in a single snapshot. During the restore process, KubeStash first applies the Druid manifest to the cluster and then restores the data into it.
Note: You can also apply the same updates in your
BackupConfigurationandRestoreSessionresources for other types of backup such as Logical Backup or Auto Backup
Before You Begin
- At first, you need to have a Kubernetes cluster, and the
kubectlcommand-line tool must be configured to communicate with your cluster. If you do not already have a cluster, you can create one by usingMinikubeorKind. - Install
KubeDBin your cluster following the steps here. - Install
KubeStashin your cluster following the steps here. - Install KubeStash
kubectlplugin following the steps here. - If you are not familiar with how KubeStash backup and restore Druid databases, please check the following guide here.
You should be familiar with the following KubeStash concepts:
To keep everything isolated, we are going to use a separate namespace called demo, dev and dev1 throughout this tutorial.
$ kubectl create ns demo
namespace/demo created
$ kubectl create ns dev
namespace/dev created
$ kubectl create ns dev1
namespace/dev1 created
Note: YAML files used in this tutorial are stored in docs/guides/druid/backup/application-level/examples directory of kubedb/docs repository.
Backup Druid
KubeStash supports backups for Druid instances for various Cluster setups. In this demonstration, we’ll focus on a Druid database with 5 type of nodes (coordinators, historicals, brokers, middlemanagers and routers). The backup and restore process is similar for other Cluster setup as well.
This section will demonstrate how to take application-level backup of a Druid database. Here, we are going to deploy a Druid database using KubeDB. Then, we are going to back up the database at the application level to a GCS bucket. Finally, we will restore the entire Druid database.
Deploy Sample Druid Database
Create External Dependency (Deep Storage):
One of the external dependency of Druid is deep storage where the segments are stored. It is a storage mechanism that Apache Druid does not provide. Amazon S3, Google Cloud Storage, or Azure Blob Storage, S3-compatible storage (like Minio), or HDFS are generally convenient options for deep storage.
In this tutorial, we will run a minio-server as deep storage in our local kind cluster using minio-operator and create a bucket named druid in it, which the deployed druid database will use.
$ helm repo add minio https://operator.min.io/
$ helm repo update minio
$ helm upgrade --install --namespace "minio-operator" --create-namespace "minio-operator" minio/operator --set operator.replicaCount=1
$ helm upgrade --install --namespace "demo" --create-namespace druid-minio minio/tenant \
--set tenant.pools[0].servers=1 \
--set tenant.pools[0].volumesPerServer=1 \
--set tenant.pools[0].size=1Gi \
--set tenant.certificate.requestAutoCert=false \
--set tenant.buckets[0].name="druid" \
--set tenant.pools[0].name="default"
Now we need to create a Secret named deep-storage-config. It contains the necessary connection information using which the druid database will connect to the deep storage.
apiVersion: v1
kind: Secret
metadata:
name: deep-storage-config
namespace: demo
stringData:
druid.storage.type: "s3"
druid.storage.bucket: "druid"
druid.storage.baseKey: "druid/segments"
druid.s3.accessKey: "minio"
druid.s3.secretKey: "minio123"
druid.s3.protocol: "http"
druid.s3.enablePathStyleAccess: "true"
druid.s3.endpoint.signingRegion: "us-east-1"
druid.s3.endpoint.url: "http://myminio-hl.demo.svc.cluster.local:9000/"
Let’s create the deep-storage-config Secret shown above:
$ kubectl create -f https://github.com/kubedb/docs/raw/v2024.11.8-rc.0/docs/guides/druid/backup/application-level/examples/deep-storage-config.yaml
secret/deep-storage-config created
Let’s deploy a sample Druid database and insert some data into it.
Create Druid CR:
Below is the YAML of a sample Druid CR that we are going to create for this tutorial:
apiVersion: kubedb.com/v1alpha2
kind: Druid
metadata:
name: sample-druid
namespace: demo
spec:
version: 30.0.0
zookeeperRef:
name: zk-dev
namespace: dev
metadataStorage:
name: my-dev1
namespace: dev1
deepStorage:
type: s3
configSecret:
name: deep-storage-config
topology:
routers:
replicas: 1
deletionPolicy: WipeOut
Here,
.spec.topologyspecifies about the clustering configuration of Druid..spec.topology.routersspecifies that 1 replica of routers node will get provisioned alongside the essential nodes..spec.metadataStoagespecifies thenameandnamespaceof theMySQLthat theKubeDBoperator will deploy as metadata storage alongsideDruid..spec.zookeeperRefspecifies thenameandnamespaceof theZooKeeperthat theKubeDBoperator will deploy alongsideDruid.
Create the above Druid CR,
$ kubectl apply -f https://github.com/kubedb/docs/raw/v2024.11.8-rc.0/docs/guides/druid/backup/application-level/examples/sample-druid.yaml
druid.kubedb.com/sample-druid created
KubeDB will deploy a Druid database according to the above specification. It will also create the necessary Secrets and Services to access the database.
Let’s check if the database is ready to use,
$ kubectl get druids.kubedb.com -n demo
NAME TYPE VERSION STATUS AGE
sample-druid kubedb.com/v1alpha2 30.0.0 Ready 4m14s
The database is Ready. Verify that KubeDB has created a Secret and a Service for this database using the following commands,
$ kubectl get secret -n demo -l=app.kubernetes.io/instance=sample-druid
NAME TYPE DATA AGE
sample-druid-admin-cred kubernetes.io/basic-auth 2 2m34s
sample-druid-config Opaque 11 2m34s
$ kubectl get service -n demo -l=app.kubernetes.io/instance=sample-druid
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sample-druid-brokers ClusterIP 10.128.135.115 <none> 8082/TCP 2m53s
sample-druid-coordinators ClusterIP 10.128.16.222 <none> 8081/TCP 2m53s
sample-druid-pods ClusterIP None <none> 8081/TCP,8090/TCP,8083/TCP,8091/TCP,8082/TCP,8888/TCP 2m53s
sample-druid-routers ClusterIP 10.128.191.186 <none> 8888/TCP 2m53s
Here, we have to use service sample-druid-routers and secret sample-druid-admin-cred to connect with the database. KubeDB creates an AppBinding CR that holds the necessary information to connect with the database.
Verify Internal Dependencies:
$ kubectl get mysql -n dev1
NAME VERSION STATUS AGE
mysql.kubedb.com/my-dev1 8.0.35 Ready 6m31s
$ kubectl get zk -n dev
NAME TYPE VERSION STATUS AGE
zookeeper.kubedb.com/zk-dev kubedb.com/v1alpha2 3.7.2 Ready 6m31s
We can see that KubeDB has deployed a MySQL and a ZooKeeper instance as External dependencies of the Druid cluster.
Verify AppBinding:
Verify that the AppBinding has been created successfully using the following command,
$ kubectl get appbindings -n demo
NAME TYPE VERSION AGE
sample-druid kubedb.com/druid 30.0.0 4m7s
$ kubectl get appbindings -n dev1
NAME TYPE VERSION AGE
my-dev1 kubedb.com/mysql 8.0.35 6m31s
$ kubectl get appbindings -n dev
NAME TYPE VERSION AGE
zk-dev kubedb.com/zookeeper 3.7.2 6m34s
Here sample-druid is the AppBinding of Druid, while my-dev1 and zk-dev are the AppBinding of MySQL and ZooKeeper instances that KubeDB has deployed as the External dependencies of Druid
Let’s check the YAML of the AppBinding of druid,
$ kubectl get appbindings -n demo sample-druid -o yaml
apiVersion: appcatalog.appscode.com/v1alpha1
kind: AppBinding
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"kubedb.com/v1alpha2","kind":"Druid","metadata":{"annotations":{},"name":"sample-druid","namespace":"demo"},"spec":{"deepStorage":{"configSecret":{"name":"deep-storage-config"},"type":"s3"},"deletionPolicy":"WipeOut","topology":{"routers":{"replicas":1}},"version":"30.0.0"}}
creationTimestamp: "2024-09-19T13:02:20Z"
generation: 1
labels:
app.kubernetes.io/component: database
app.kubernetes.io/instance: sample-druid
app.kubernetes.io/managed-by: kubedb.com
app.kubernetes.io/name: druids.kubedb.com
name: sample-druid
namespace: demo
ownerReferences:
- apiVersion: kubedb.com/v1alpha2
blockOwnerDeletion: true
controller: true
kind: Druid
name: sample-druid
uid: cdbc2414-0dd1-4573-9532-e96b9094a443
resourceVersion: "1610820"
uid: 8430d22d-e715-454a-8a83-e30e40cbeb14
spec:
appRef:
apiGroup: kubedb.com
kind: Druid
name: sample-druid
namespace: demo
clientConfig:
service:
name: sample-druid-pods
port: 8888
scheme: http
url: http://sample-druid-coordinators-0.sample-druid-pods.demo.svc.cluster.local:8081,http://sample-druid-overlords-0.sample-druid-pods.demo.svc.cluster.local:8090,http://sample-druid-middlemanagers-0.sample-druid-pods.demo.svc.cluster.local:8091,http://sample-druid-historicals-0.sample-druid-pods.demo.svc.cluster.local:8083,http://sample-druid-brokers-0.sample-druid-pods.demo.svc.cluster.local:8082,http://sample-druid-routers-0.sample-druid-pods.demo.svc.cluster.local:8888
secret:
name: sample-druid-admin-cred
type: kubedb.com/druid
version: 30.0.0
KubeStash uses the AppBinding CR to connect with the target database. It requires the following two fields to set in AppBinding’s .spec section.
.spec.clientConfig.service.namespecifies the name of the Service that connects to the database..spec.secretspecifies the name of the Secret that holds necessary credentials to access the database.spec.typespecifies the types of the app that this AppBinding is pointing to. KubeDB generated AppBinding follows the following format:<app group>/<app resource type>.
Insert Sample Data:
We can access the web console of Druid database from any browser by port-forwarding the routers. Let’s port-forward the port 8888 to local machine:
kubectl port-forward -n demo svc/sample-druid-routers 8888
Forwarding from 127.0.0.1:8888 -> 8888
Forwarding from [::1]:8888 -> 8888
Now hit the http://localhost:8888 from any browser, and you will be prompted to provide the credential of the druid database. By following the steps discussed below, you can get the credential generated by the KubeDB operator for your Druid database.
Connection information:
Username:
$ kubectl get secret -n demo sample-druid-admin-cred -o jsonpath='{.data.username}' | base64 -d adminPassword:
$ kubectl get secret -n demo sample-druid-admin-cred -o jsonpath='{.data.password}' | base64 -d DqG5E63NtklAkxqC
After providing the credentials correctly, you should be able to access the web console like shown below.
Now select the Load Data option and then select Batch - classic from the drop-down menu.
Select Example data and click Load example to insert the example Wikipedia Edits datasource.
After clicking Next multiple times, click Submit
Within a minute status of the ingestion task should become SUCCESS
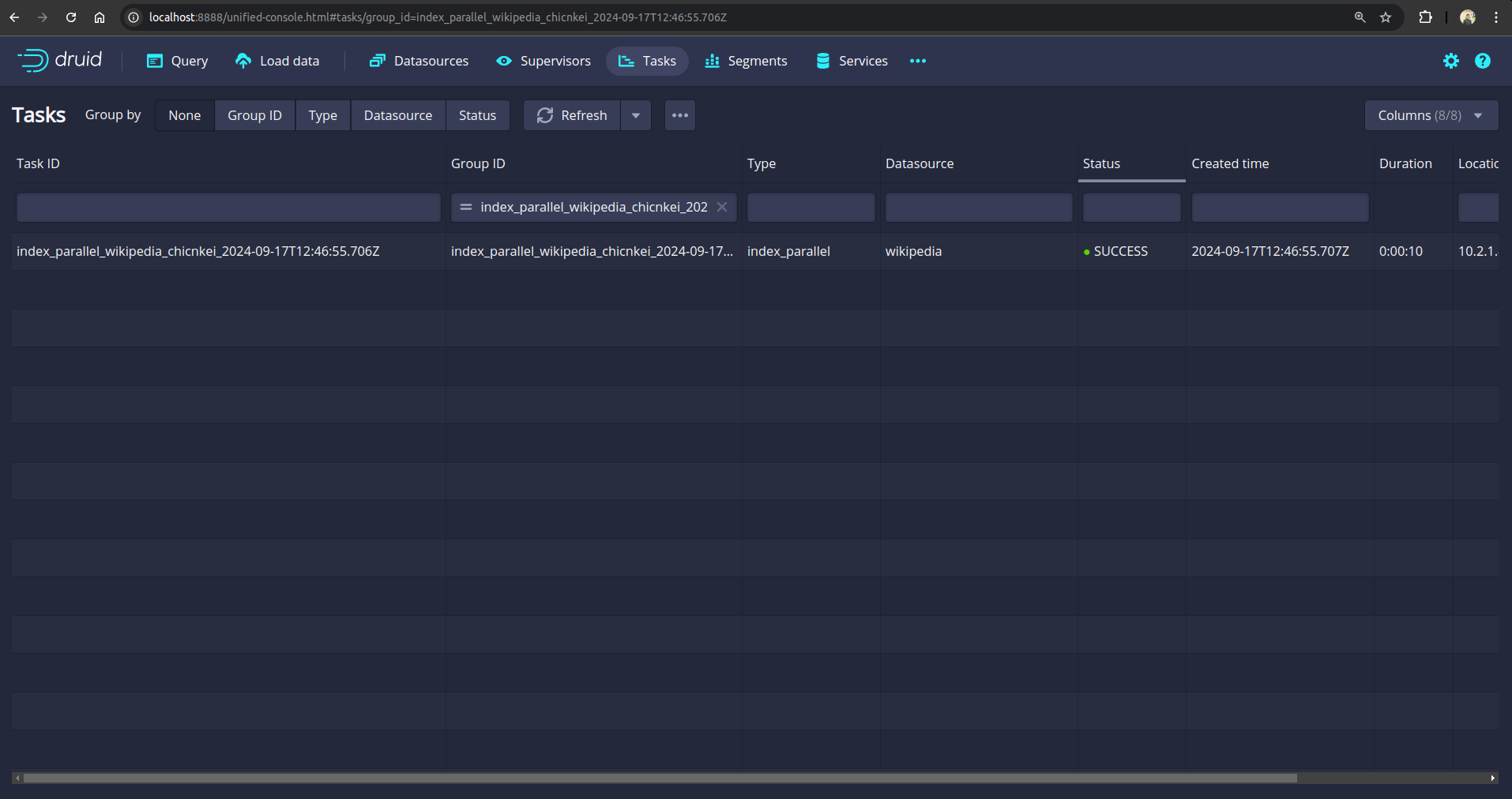
Now, we are ready to backup the database.
Prepare Backend
We are going to store our backed up data into a GCS bucket. We have to create a Secret with necessary credentials and a BackupStorage CR to use this backend. If you want to use a different backend, please read the respective backend configuration doc from here.
Create Secret:
Let’s create a secret called gcs-secret with access credentials to our desired GCS bucket,
$ echo -n '<your-project-id>' > GOOGLE_PROJECT_ID
$ cat /path/to/downloaded-sa-key.json > GOOGLE_SERVICE_ACCOUNT_JSON_KEY
$ kubectl create secret generic -n demo gcs-secret \
--from-file=./GOOGLE_PROJECT_ID \
--from-file=./GOOGLE_SERVICE_ACCOUNT_JSON_KEY
secret/gcs-secret created
Create BackupStorage:
Now, create a BackupStorage using this secret. Below is the YAML of BackupStorage CR we are going to create,
apiVersion: storage.kubestash.com/v1alpha1
kind: BackupStorage
metadata:
name: gcs-storage
namespace: demo
spec:
storage:
provider: gcs
gcs:
bucket: kubestash-qa
prefix: druid
secretName: gcs-secret
usagePolicy:
allowedNamespaces:
from: All
default: true
deletionPolicy: Delete
Let’s create the BackupStorage we have shown above,
$ kubectl apply -f https://github.com/kubedb/docs/raw/v2024.11.8-rc.0/docs/guides/druid/backup/application-level/examples/backupstorage.yaml
backupstorage.storage.kubestash.com/gcs-storage created
Now, we are ready to backup our database to our desired backend.
Create RetentionPolicy:
Now, let’s create a RetentionPolicy to specify how the old Snapshots should be cleaned up.
Below is the YAML of the RetentionPolicy object that we are going to create,
apiVersion: storage.kubestash.com/v1alpha1
kind: RetentionPolicy
metadata:
name: demo-retention
namespace: demo
spec:
default: true
failedSnapshots:
last: 2
maxRetentionPeriod: 2mo
successfulSnapshots:
last: 5
usagePolicy:
allowedNamespaces:
from: All
Let’s create the above RetentionPolicy,
$ kubectl apply -f https://github.com/kubedb/docs/raw/v2024.11.8-rc.0/docs/guides/druid/backup/application-level/examples/retentionpolicy.yaml
retentionpolicy.storage.kubestash.com/demo-retention created
Backup
We have to create a BackupConfiguration targeting respective sample-druid Druid database. Then, KubeStash will create a CronJob for each session to take periodic backup of that database.
At first, we need to create a secret with a Restic password for backup data encryption.
Create Secret:
Let’s create a secret called encrypt-secret with the Restic password,
$ echo -n 'changeit' > RESTIC_PASSWORD
$ kubectl create secret generic -n demo encrypt-secret \
--from-file=./RESTIC_PASSWORD \
secret "encrypt-secret" created
Create RBAC
To take backup of the Druid Database alongside with its dependencies, KubeStash creates a backup Job. Consequently, if the dependencies are in different namespaces, then this Job requires read, list, watch and create permission for some of the cluster resources. This includes resources for the dependencies (MySQL, ZooKeeper and PostgreSQL) as well as Appbinding, Secrets and Configmaps. By default, KubeStash does not grant such cluster-wide permissions. We have to provide the necessary permissions manually.
Here, is the YAML of the ServiceAccount, ClusterRole, and RoleBinding that we are going to use for granting the necessary permissions. We will create two RoleBinding in both dev and dev1 because we are going to deploy ZooKeeper in dev and MySQL in dev1 namespace.
apiVersion: v1
kind: ServiceAccount
metadata:
name: cluster-resource-reader
namespace: demo
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cluster-resource-reader
rules:
- apiGroups: ["kubedb.com"]
resources: ["zookeepers", "mysqls", "postgreses"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["appcatalog.appscode.com"]
resources: ["appbindings"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: [""]
resources: ["secrets", "configmaps"]
verbs: ["get", "list", "watch", "create"]
---
# RoleBinding for the dev namespace
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: cluster-resource-reader
namespace: dev
subjects:
- kind: ServiceAccount
name: cluster-resource-reader
namespace: demo
roleRef:
kind: ClusterRole
name: cluster-resource-reader
apiGroup: rbac.authorization.k8s.io
---
# RoleBinding for the dev1 namespace
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: cluster-resource-reader
namespace: dev1
subjects:
- kind: ServiceAccount
name: cluster-resource-reader
namespace: demo
roleRef:
kind: ClusterRole
name: cluster-resource-reader
apiGroup: rbac.authorization.k8s.io
Let’s create the RBAC resources we have shown above,
$ kubectl apply -f https://github.com/kubedb/docs/raw/v2024.11.8-rc.0/docs/guides/druid/backup/cross-ns-dependencies/examples/rbac.yaml
serviceaccount/cluster-resource-reader created
clusterrole.rbac.authorization.k8s.io/cluster-resource-reader created
rolebinding.rbac.authorization.k8s.io/cluster-resource-reader created
rolebinding.rbac.authorization.k8s.io/cluster-resource-reader created
Create BackupConfiguration:
Below is the YAML for BackupConfiguration CR to take application-level backup of the sample-druid database that we have deployed earlier,
apiVersion: core.kubestash.com/v1alpha1
kind: BackupConfiguration
metadata:
name: sample-druid-backup
namespace: demo
spec:
target:
apiGroup: kubedb.com
kind: Druid
namespace: demo
name: sample-druid
backends:
- name: gcs-backend
storageRef:
namespace: demo
name: gcs-storage
retentionPolicy:
name: demo-retention
namespace: demo
sessions:
- name: frequent-backup
scheduler:
schedule: "*/5 * * * *"
jobTemplate:
backoffLimit: 1
repositories:
- name: gcs-druid-repo
backend: gcs-backend
directory: /druid
encryptionSecret:
name: encrypt-secret
namespace: demo
addon:
name: druid-addon
tasks:
- name: manifest-backup
- name: mysql-metadata-storage-backup
jobTemplate:
spec:
serviceAccountName: cluster-resource-reader
.spec.sessions[*].schedulespecifies that we want to backup at5 minutesinterval..spec.targetrefers to the targetedsample-druidDruid database that we created earlier..spec.sessions[*].addon.tasks[*].name[*]specifies that both themanifest-backupandmysql-metadata-storage-backuptasks will be executed.spec.sessions[*].addon.jobTemplate.spec.serviceAccountNamespecifies theServiceAccountname that we have created earlier with sufficient permission indevanddev1namespace.
Note:
- To create
BackupConfigurationfor druid withPostgreSQLas metadata storage update thespec.sessions[*].addon.tasks.namefrommysql-metadata-storage-backuptopostgres-metadata-storage-restore.- When we backup a
Druid, KubeStash operator will also take backup of the dependency of theMySQLandZooKeepercluster as well.
Let’s create the BackupConfiguration CR that we have shown above,
$ kubectl apply -f https://github.com/kubedb/docs/raw/v2024.11.8-rc.0/docs/guides/druid/backup/application-level/examples/backupconfiguration.yaml
backupconfiguration.core.kubestash.com/sample-druid-backup created
Verify Backup Setup Successful
If everything goes well, the phase of the BackupConfiguration should be Ready. The Ready phase indicates that the backup setup is successful. Let’s verify the Phase of the BackupConfiguration,
$ kubectl get backupconfiguration -n demo
NAME PHASE PAUSED AGE
sample-druid-backup Ready 2m50s
Additionally, we can verify that the Repository specified in the BackupConfiguration has been created using the following command,
$ kubectl get repo -n demo
NAME INTEGRITY SNAPSHOT-COUNT SIZE PHASE LAST-SUCCESSFUL-BACKUP AGE
gcs-druid-repo 0 0 B Ready 3m
KubeStash keeps the backup for Repository YAMLs. If we navigate to the GCS bucket, we will see the Repository YAML stored in the demo/druid directory.
Verify CronJob:
It will also create a CronJob with the schedule specified in spec.sessions[*].scheduler.schedule field of BackupConfiguration CR.
Verify that the CronJob has been created using the following command,
$ kubectl get cronjob -n demo
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
trigger-sample-druid-backup-frequent-backup */5 * * * * 0 2m45s 3m25s
Verify BackupSession:
KubeStash triggers an instant backup as soon as the BackupConfiguration is ready. After that, backups are scheduled according to the specified schedule.
Run the following command to watch BackupSession CR,
$ kubectl get backupsession -n demo -w
NAME INVOKER-TYPE INVOKER-NAME PHASE DURATION AGE
sample-druid-backup-frequent-backup-1724065200 BackupConfiguration sample-druid-backup Succeeded 7m22s
We can see from the above output that the backup session has succeeded. Now, we are going to verify whether the backed up data has been stored in the backend.
Verify Backup:
Once a backup is complete, KubeStash will update the respective Repository CR to reflect the backup. Check that the repository sample-druid-backup has been updated by the following command,
$ kubectl get repository -n demo gcs-druid-repo
NAME INTEGRITY SNAPSHOT-COUNT SIZE PHASE LAST-SUCCESSFUL-BACKUP AGE
gcs-druid-repo true 4 664.979 KiB Ready 2m55s 4h56m
At this moment we have one Snapshot. Run the following command to check the respective Snapshot which represents the state of a backup run for an application.
$ kubectl get snapshots -n demo -l=kubestash.com/repo-name=gcs-druid-repo
NAME REPOSITORY SESSION SNAPSHOT-TIME DELETION-POLICY PHASE AGE
gcs-druid-repo-sample-druid-backup-frequent-backup-1726830540 gcs-druid-repo frequent-backup 2024-09-20T11:09:00Z Delete Succeeded 3m13s
Note: KubeStash creates a
Snapshotwith the following labels:
kubestash.com/app-ref-kind: <target-kind>kubestash.com/app-ref-name: <target-name>kubestash.com/app-ref-namespace: <target-namespace>kubestash.com/repo-name: <repository-name>These labels can be used to watch only the
Snapshots related to our target Database orRepository.
If we check the YAML of the Snapshot, we can find the information about the backed up components of the Database.
$ kubectl get snapshots -n demo gcs-druid-repo-sample-druid-backup-frequent-backup-1725359100 -oyaml
apiVersion: storage.kubestash.com/v1alpha1
kind: Snapshot
metadata:
annotations:
kubedb.com/db-version: 30.0.0
creationTimestamp: "2024-09-20T11:09:00Z"
finalizers:
- kubestash.com/cleanup
generation: 1
labels:
kubestash.com/app-ref-kind: Druid
kubestash.com/app-ref-name: sample-druid
kubestash.com/app-ref-namespace: demo
kubestash.com/repo-name: gcs-druid-repo
name: gcs-druid-repo-sample-druid-backup-frequent-backup-1726830540
namespace: demo
ownerReferences:
- apiVersion: storage.kubestash.com/v1alpha1
blockOwnerDeletion: true
controller: true
kind: Repository
name: gcs-druid-repo
uid: d894aad3-ac0d-4c8f-b165-9f9f1085ef3a
resourceVersion: "1720138"
uid: 348fe907-9207-4a71-953c-6cafa80ba3f7
spec:
appRef:
apiGroup: kubedb.com
kind: Druid
name: sample-druid
namespace: demo
backupSession: sample-druid-backup-frequent-backup-1726830540
deletionPolicy: Delete
repository: gcs-druid-repo
session: frequent-backup
snapshotID: 01J87HXY4439P70MKGWS8RZM7E
type: FullBackup
version: v1
status:
components:
dump:
driver: Restic
duration: 10.312603282s
integrity: true
path: repository/v1/frequent-backup/dump
phase: Succeeded
resticStats:
- hostPath: dumpfile.sql
id: 647a7123a66423a81fa21ac77128e46587ddae3e9c9426537a30ad1c9a8e1843
size: 3.807 MiB
uploaded: 3.807 MiB
size: 652.853 KiB
manifest:
driver: Restic
duration: 10.457007184s
integrity: true
path: repository/v1/frequent-backup/manifest
phase: Succeeded
resticStats:
- hostPath: /kubestash-tmp/manifest
id: 069ad1c6dae59fd086aa9771289fc4dad6d076afbc11180e3b1cd8083cd01691
size: 13.599 KiB
uploaded: 4.268 KiB
size: 12.127 KiB
conditions:
- lastTransitionTime: "2024-09-20T11:09:00Z"
message: Recent snapshot list updated successfully
reason: SuccessfullyUpdatedRecentSnapshotList
status: "True"
type: RecentSnapshotListUpdated
- lastTransitionTime: "2024-09-20T11:10:07Z"
message: Metadata uploaded to backend successfully
reason: SuccessfullyUploadedSnapshotMetadata
status: "True"
type: SnapshotMetadataUploaded
integrity: true
phase: Succeeded
size: 664.979 KiB
snapshotTime: "2024-09-20T11:09:00Z"
totalComponents: 2
KubeStash uses the
mysqldump/postgresdumpcommand to take backups of the metadata storage of the target Druid databases. Therefore, the component name forlogical backupsis set asdump. KubeStash set component name asmanifestfor themanifest backupof Druid databases.
Now, if we navigate to the GCS bucket, we will see the backed up data stored in the demo/druid/repository/v1/frequent-backup/dump directory. KubeStash also keeps the backup for Snapshot YAMLs, which can be found in the demo/dep/snapshots directory.
Note: KubeStash stores all dumped data encrypted in the backup directory, meaning it remains unreadable until decrypted.
Delete Druid
Now, we are going to delete the Druid cluster that we have deployed and took backup earlier.
$ kubectl delete druid -n demo sample-druid
druid.kubedb.com "sample-druid" deleted
The dependencies of druid with name zk-dev and my-dev1 will also be deleted from their respective namespaces.
Restore
In this section, we are going to restore the entire database from the backup that we have taken in the previous section. For this tutorial, we will restore the database in the same namespaces that they were in before.
Create RestoreSession:
We need to create a RestoreSession CR.
Below, is the contents of YAML file of the RestoreSession CR that we are going to create to restore the entire database.
apiVersion: core.kubestash.com/v1alpha1
kind: RestoreSession
metadata:
name: restore-sample-druid
namespace: demo
spec:
manifestOptions:
druid:
db: true
dataSource:
repository: gcs-druid-repo
snapshot: latest
encryptionSecret:
name: encrypt-secret
namespace: demo
addon:
name: druid-addon
tasks:
- name: mysql-metadata-storage-restore
- name: manifest-restore
jobTemplate:
spec:
serviceAccountName: cluster-resource-reader
Here,
.spec.manifestOptions.druid.dbspecifies whether to restore the DB manifest or not..spec.dataSource.repositoryspecifies the Repository object that holds the backed up data..spec.dataSource.snapshotspecifies to restore from latestSnapshot..spec.addon.tasks[*]specifies that both themanifest-restoreandlogical-backup-restoretasks.spec.sessions[*].addon.jobTemplate.spec.serviceAccountNamespecifies theServiceAccountname that we have created earlier with sufficient permission indevanddev1namespace.
Note:
- When we restore a
Druidwithspec.metadataStorage.externallyManagedset tofalse(which isfalseby default), then KubeStash operator will also restore the metadataStorage automatically.- Similarly, if
spec.zooKeeper.externallyManagedisfalse(which is alsofalseby default) then KubeStash operator will also restore the zookeeper instance automatically.- For externally managed metadata storage and zookeeper however, user needs to specify it in
spec.manifestOptions.mySQL/spec.manifestOptions.postgres/spec.manifestOptions.zooKeeperto restore those.
Let’s create the RestoreSession CRD object we have shown above,
$ kubectl apply -f https://github.com/kubedb/docs/raw/v2024.11.8-rc.0/docs/guides/druid/backup/application-level/examples/restoresession.yaml
restoresession.core.kubestash.com/restore-sample-druid created
Once, you have created the RestoreSession object, KubeStash will create restore Job. Run the following command to watch the phase of the RestoreSession object,
$ watch kubectl get restoresession -n demo
Every 2.0s: kubectl get restores... AppsCode-PC-03: Wed Aug 21 10:44:05 2024
NAME REPOSITORY FAILURE-POLICY PHASE DURATION AGE
sample-restore gcs-demo-repo Succeeded 3s 53s
The Succeeded phase means that the restore process has been completed successfully.
Verify Restored Druid Manifest:
In this section, we will verify whether the desired Druid database manifest has been successfully applied to the cluster.
$ kubectl get druids.kubedb.com -n demo
NAME VERSION STATUS AGE
restored-druid 30.0.0 Ready 6m26s
The output confirms that the Druid database has been successfully created with the same configuration as it had at the time of backup.
Verify the dependencies have been restored:
$ $ kubectl get mysql -n dev1
NAME VERSION STATUS AGE
mysql.kubedb.com/my-dev1 8.0.35 Ready 6m30s
$ kubectl get zk -n dev
NAME TYPE VERSION STATUS AGE
zookeeper.kubedb.com/zk-dev kubedb.com/v1alpha2 3.7.2 Ready 6m30s
The output confirms that the MySQL and ZooKeper databases have been successfully created with the same configuration as it had at the time of backup.
Verify Restored Data:
In this section, we are going to verify whether the desired data has been restored successfully. We are going to connect to the database server and check whether the database and the table we created earlier in the original database are restored.
At first, check if the database has gone into Ready state by the following command,
$ kubectl get druid -n demo restored-druid
NAME VERSION STATUS AGE
restored-druid 30.0.0 Ready 34m
Now, let’s verify if our datasource wikipedia exists or not. For that, first find out the database Sevices by the following command,
Now access the web console of Druid database from any browser by port-forwarding the routers. Let’s port-forward the port 8888 to local machine:
$ kubectl get svc -n demo --selector="app.kubernetes.io/instance=restored-druid"
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
restored-druid-brokers ClusterIP 10.128.74.54 <none> 8082/TCP 10m
restored-druid-coordinators ClusterIP 10.128.30.124 <none> 8081/TCP 10m
restored-druid-pods ClusterIP None <none> 8081/TCP,8090/TCP,8083/TCP,8091/TCP,8082/TCP,8888/TCP 10m
restored-druid-routers ClusterIP 10.128.228.193 <none> 8888/TCP 10m
kubectl port-forward -n demo svc/restored-druid-routers 8888
Forwarding from 127.0.0.1:8888 -> 8888
Forwarding from [::1]:8888 -> 8888
Then hit the http://localhost:8888 from any browser, and you will be prompted to provide the credential of the druid database. By following the steps discussed below, you can get the credential generated by the KubeDB operator for your Druid database.
Connection information:
Username:
$ kubectl get secret -n demo restored-druid-admin-cred -o jsonpath='{.data.username}' | base64 -d adminPassword:
$ kubectl get secret -n demo restored-druid-admin-cred -o jsonpath='{.data.password}' | base64 -d DqG5E63NtklAkxqC
After providing the credentials correctly, you should be able to access the web console like shown below. Now if you go to the Datasources section, you will see that our ingested datasource wikipedia exists in the list.
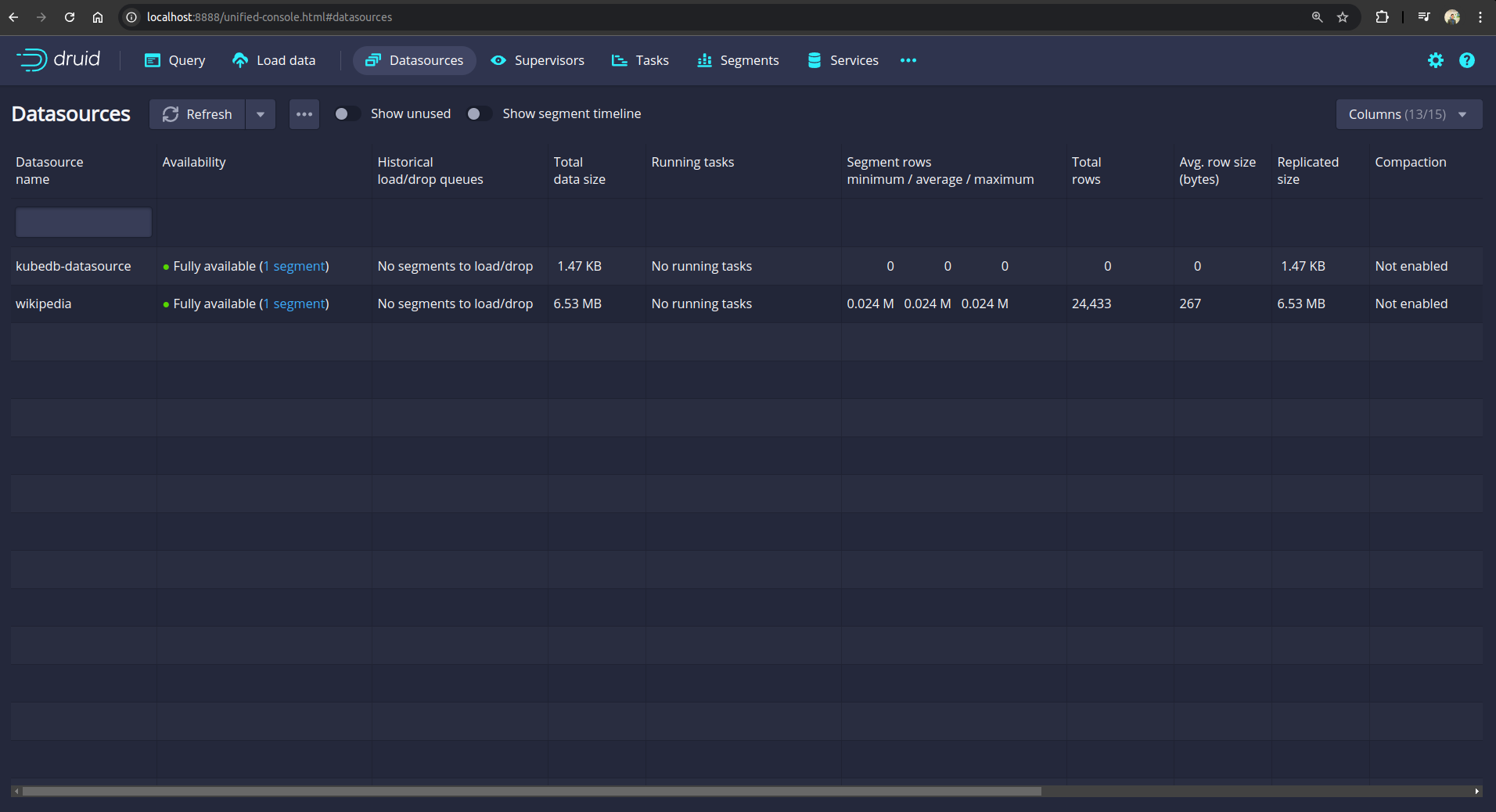
So, from the above screenshot, we can see that the wikipedia datasource we have ingested earlier in the original database and now, it is restored successfully.
Cleanup
To cleanup the Kubernetes resources created by this tutorial, run:
kubectl delete backupconfigurations.core.kubestash.com -n demo sample-druid-backup
kubectl delete backupstorage -n demo gcs-storage
kubectl delete secret -n demo gcs-secret
kubectl delete secret -n demo encrypt-secret
kubectl delete retentionpolicies.storage.kubestash.com -n demo demo-retention
kubectl delete restoresessions.core.kubestash.com -n demo restore-sample-druid
kubectl delete druid -n demo sample-druid
kubectl delete druid -n dev restored-druid