



































You are looking at the documentation of a prior release. To read the documentation of the latest release, please
visit here.
New to KubeDB? Please start here.
Druid QuickStart
This tutorial will show you how to use KubeDB to run an Apache Druid.
Before You Begin
At first, you need to have a Kubernetes cluster, and the kubectl command-line tool must be configured to communicate with your cluster. If you do not already have a cluster, you can create one by using kind.
Now, install KubeDB cli on your workstation and KubeDB operator in your cluster following the steps here and make sure install with helm command including the flags --set global.featureGates.Druid=true to ensure Druid CRD and --set global.featureGates.ZooKeeper=true to ensure ZooKeeper CRD as Druid depends on ZooKeeper for external dependency.
To keep things isolated, this tutorial uses a separate namespace called demo throughout this tutorial.
$ kubectl create namespace demo
namespace/demo created
$ kubectl get namespace
NAME STATUS AGE
demo Active 9s
Note: YAML files used in this tutorial are stored in guides/druid/quickstart/overview/yamls folder in GitHub repository kubedb/docs.
We have designed this tutorial to demonstrate a production setup of KubeDB managed Apache Druid. If you just want to try out KubeDB, you can bypass some safety features following the tips here.
Find Available StorageClass
We will have to provide StorageClass in Druid CRD specification. Check available StorageClass in your cluster using the following command,
$ kubectl get storageclass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
standard (default) rancher.io/local-path Delete WaitForFirstConsumer false 14h
Here, we have standard StorageClass in our cluster from Local Path Provisioner.
Find Available DruidVersion
When you install the KubeDB operator, it registers a CRD named DruidVersion. The installation process comes with a set of tested DruidVersion objects. Let’s check available DruidVersions by,
$ kubectl get druidversion
NAME VERSION DB_IMAGE DEPRECATED AGE
28.0.1 28.0.1 ghcr.io/appscode-images/druid:28.0.1 4h47m
Notice the DEPRECATED column. Here, true means that this DruidVersion is deprecated for the current KubeDB version. KubeDB will not work for deprecated DruidVersion. You can also use the short from drversion to check available DruidVersions.
In this tutorial, we will use 28.0.1 DruidVersion CR to create a Druid cluster.
Get External Dependencies Ready
Deep Storage
One of the external dependency of Druid is deep storage where the segments are stored. It is a storage mechanism that Apache Druid does not provide. Amazon S3, Google Cloud Storage, or Azure Blob Storage, S3-compatible storage (like Minio), or HDFS are generally convenient options for deep storage.
In this tutorial, we will run a minio-server as deep storage in our local kind cluster using minio-operator and create a bucket named druid in it, which the deployed druid database will use.
$ helm repo add minio https://operator.min.io/
$ helm repo update minio
$ helm upgrade --install --namespace "minio-operator" --create-namespace "minio-operator" minio/operator --set operator.replicaCount=1
$ helm upgrade --install --namespace "demo" --create-namespace druid-minio minio/tenant \
--set tenant.pools[0].servers=1 \
--set tenant.pools[0].volumesPerServer=1 \
--set tenant.pools[0].size=1Gi \
--set tenant.certificate.requestAutoCert=false \
--set tenant.buckets[0].name="druid" \
--set tenant.pools[0].name="default"
Now we need to create a Secret named deep-storage-config. It contains the necessary connection information using which the druid database will connect to the deep storage.
apiVersion: v1
kind: Secret
metadata:
name: deep-storage-config
namespace: demo
stringData:
druid.storage.type: "s3"
druid.storage.bucket: "druid"
druid.storage.baseKey: "druid/segments"
druid.s3.accessKey: "minio"
druid.s3.secretKey: "minio123"
druid.s3.protocol: "http"
druid.s3.enablePathStyleAccess: "true"
druid.s3.endpoint.signingRegion: "us-east-1"
druid.s3.endpoint.url: "http://myminio-hl.demo.svc.cluster.local:9000/"
Let’s create the deep-storage-config Secret shown above:
$ kubectl create -f https://github.com/kubedb/docs/raw/v2024.11.8-rc.0/docs/examples/druid/quickstart/deep-storage-config.yaml
secret/deep-storage-config created
You can also use options like Amazon S3, Google Cloud Storage, Azure Blob Storage or HDFS and create a connection information Secret like this, and you are good to go.
Metadata Storage
Druid uses the metadata store to house various metadata about the system, but not to store the actual data. The metadata store retains all metadata essential for a Druid cluster to work. Apache Derby is the default metadata store for Druid, however, it is not suitable for production. MySQL and PostgreSQL are more production suitable metadata stores.
Luckily, PostgreSQL and MySQL both are readily available in KubeDB as CRD and KubeDB operator will automatically create a MySQL cluster and create a database in it named druid by default.
If you choose to use PostgreSQL as metadata storage, you can simply mention that in the spec.metadataStorage.type of the Druid CR and KubeDB operator will deploy a PostgreSQL cluster for druid to use.
ZooKeeper
Apache Druid uses Apache ZooKeeper (ZK) for management of current cluster state i.e. internal service discovery, coordination, and leader election.
Fortunately, KubeDB also has support for ZooKeeper and KubeDB operator will automatically create a ZooKeeper cluster for druid to use.
Create a Druid Cluster
The KubeDB operator implements a Druid CRD to define the specification of Druid.
The Druid instance used for this tutorial:
apiVersion: kubedb.com/v1alpha2
kind: Druid
metadata:
name: druid-quickstart
namespace: demo
spec:
version: 28.0.1
deepStorage:
type: s3
configSecret:
name: deep-storage-config
topology:
routers:
replicas: 1
deletionPolicy: Delete
serviceTemplates:
- alias: primary
spec:
type: LoadBalancer
ports:
- name: routers
port: 8888
Here,
spec.version- is the name of the DruidVersion CR. Here, a Druid of version28.0.1will be created.spec.deepStorage- contains the information of deep storage configuration withspec.deepStorage.typebeing the deep storage type andspec.deepStorage.configSecretis a reference to the configuration secret.spec.topology- is the definition of the topology that will be deployed. The required nodes such ascoordinators,historicals,middleManagers, andbrokerswill be deployed by default with one replica. You can also add optional nodes includingroutersandoverlordsin the topology.spec.deletionPolicyspecifies what KubeDB should do when a user try to delete Druid CR. Deletion policyDeletewill delete the database pods and PVC when the Druid CR is deleted.
Note:
spec.topology.historicals(/middleManagers).storagesection is used to create PVC for database pod. It will create PVC with storage size specified in thestorage.resources.requestsfield. Don’t specifylimitshere. PVC does not get resized automatically.
Let’s create the Druid CR that is shown above:
$ kubectl apply -f https://github.com/kubedb/docs/raw/v2024.11.8-rc.0/docs/examples/druid/quickstart/druid-quickstart.yaml
druid.kubedb.com/druid-quickstart created
The Druid’s STATUS will go from Provisioning to Ready state within few minutes. Once the STATUS is Ready, you are ready to use the newly provisioned Druid cluster.
$ kubectl get druid -n demo -w
NAME TYPE VERSION STATUS AGE
druid-quickstart kubedb.com/v1alpha2 28.0.1 Provisioning 17s
druid-quickstart kubedb.com/v1alpha2 28.0.1 Provisioning 28s
.
.
druid-quickstart kubedb.com/v1alpha2 28.0.1 Ready 82s
Describe the Druid object to observe the progress if something goes wrong or the status is not changing for a long period of time:
$ kubectl describe druid -n demo druid-quickstart
Name: druid-quickstart
Namespace: demo
Labels: <none>
Annotations: <none>
API Version: kubedb.com/v1alpha2
Kind: Druid
Metadata:
Creation Timestamp: 2024-07-16T10:35:14Z
Finalizers:
kubedb.com/druid
Generation: 1
Managed Fields:
API Version: kubedb.com/v1alpha2
Fields Type: FieldsV1
fieldsV1:
f:metadata:
f:finalizers:
.:
v:"kubedb.com/druid":
Manager: druid-operator
Operation: Update
Time: 2024-07-16T10:35:14Z
API Version: kubedb.com/v1alpha2
Fields Type: FieldsV1
fieldsV1:
f:metadata:
f:annotations:
.:
f:kubectl.kubernetes.io/last-applied-configuration:
f:spec:
.:
f:deepStorage:
.:
f:configSecret:
f:type:
f:healthChecker:
.:
f:failureThreshold:
f:periodSeconds:
f:timeoutSeconds:
f:serviceTemplates:
f:topology:
.:
f:routers:
.:
f:replicas:
f:version:
Manager: kubectl-client-side-apply
Operation: Update
Time: 2024-07-16T10:35:14Z
API Version: kubedb.com/v1alpha2
Fields Type: FieldsV1
fieldsV1:
f:status:
.:
f:conditions:
f:phase:
Manager: druid-operator
Operation: Update
Subresource: status
Time: 2024-07-16T10:38:33Z
Resource Version: 149232
UID: 5a52ae03-1e4a-4262-9d04-384025c372db
Spec:
Auth Secret:
Name: druid-quickstart-admin-cred
Deep Storage:
Config Secret:
Name: deep-storage-config
Type: s3
Deletion Policy: Delete
Disable Security: false
Health Checker:
Failure Threshold: 3
Period Seconds: 30
Timeout Seconds: 10
Metadata Storage:
Create Tables: true
Linked DB: druid
Name: druid-quickstart-mysql-metadata
Namespace: demo
Type: MySQL
Version: 8.0.35
Service Templates:
Alias: primary
Metadata:
Spec:
Ports:
Name: routers
Port: 8888
Type: LoadBalancer
Topology:
Brokers:
Pod Template:
Controller:
Metadata:
Spec:
Containers:
Name: druid
Resources:
Limits:
Memory: 1Gi
Requests:
Cpu: 500m
Memory: 1Gi
Security Context:
Allow Privilege Escalation: false
Capabilities:
Drop:
ALL
Run As Non Root: true
Run As User: 1000
Seccomp Profile:
Type: RuntimeDefault
Init Containers:
Name: init-druid
Resources:
Limits:
Memory: 512Mi
Requests:
Cpu: 200m
Memory: 512Mi
Security Context:
Allow Privilege Escalation: false
Capabilities:
Drop:
ALL
Run As Non Root: true
Run As User: 1000
Seccomp Profile:
Type: RuntimeDefault
Pod Placement Policy:
Name: default
Security Context:
Fs Group: 1000
Replicas: 1
Coordinators:
Pod Template:
Controller:
Metadata:
Spec:
Containers:
Name: druid
Resources:
Limits:
Memory: 1Gi
Requests:
Cpu: 500m
Memory: 1Gi
Security Context:
Allow Privilege Escalation: false
Capabilities:
Drop:
ALL
Run As Non Root: true
Run As User: 1000
Seccomp Profile:
Type: RuntimeDefault
Init Containers:
Name: init-druid
Resources:
Limits:
Memory: 512Mi
Requests:
Cpu: 200m
Memory: 512Mi
Security Context:
Allow Privilege Escalation: false
Capabilities:
Drop:
ALL
Run As Non Root: true
Run As User: 1000
Seccomp Profile:
Type: RuntimeDefault
Pod Placement Policy:
Name: default
Security Context:
Fs Group: 1000
Replicas: 1
Historicals:
Pod Template:
Controller:
Metadata:
Spec:
Containers:
Name: druid
Resources:
Limits:
Memory: 1Gi
Requests:
Cpu: 500m
Memory: 1Gi
Security Context:
Allow Privilege Escalation: false
Capabilities:
Drop:
ALL
Run As Non Root: true
Run As User: 1000
Seccomp Profile:
Type: RuntimeDefault
Init Containers:
Name: init-druid
Resources:
Limits:
Memory: 512Mi
Requests:
Cpu: 200m
Memory: 512Mi
Security Context:
Allow Privilege Escalation: false
Capabilities:
Drop:
ALL
Run As Non Root: true
Run As User: 1000
Seccomp Profile:
Type: RuntimeDefault
Pod Placement Policy:
Name: default
Security Context:
Fs Group: 1000
Replicas: 1
Storage:
Access Modes:
ReadWriteOnce
Resources:
Requests:
Storage: 1Gi
Storage Type: Durable
Middle Managers:
Pod Template:
Controller:
Metadata:
Spec:
Containers:
Name: druid
Resources:
Limits:
Memory: 2560Mi
Requests:
Cpu: 500m
Memory: 2560Mi
Security Context:
Allow Privilege Escalation: false
Capabilities:
Drop:
ALL
Run As Non Root: true
Run As User: 1000
Seccomp Profile:
Type: RuntimeDefault
Init Containers:
Name: init-druid
Resources:
Limits:
Memory: 512Mi
Requests:
Cpu: 200m
Memory: 512Mi
Security Context:
Allow Privilege Escalation: false
Capabilities:
Drop:
ALL
Run As Non Root: true
Run As User: 1000
Seccomp Profile:
Type: RuntimeDefault
Pod Placement Policy:
Name: default
Security Context:
Fs Group: 1000
Replicas: 1
Storage:
Access Modes:
ReadWriteOnce
Resources:
Requests:
Storage: 1Gi
Storage Type: Durable
Routers:
Pod Template:
Controller:
Metadata:
Spec:
Containers:
Name: druid
Resources:
Limits:
Memory: 1Gi
Requests:
Cpu: 500m
Memory: 1Gi
Security Context:
Allow Privilege Escalation: false
Capabilities:
Drop:
ALL
Run As Non Root: true
Run As User: 1000
Seccomp Profile:
Type: RuntimeDefault
Init Containers:
Name: init-druid
Resources:
Limits:
Memory: 512Mi
Requests:
Cpu: 200m
Memory: 512Mi
Security Context:
Allow Privilege Escalation: false
Capabilities:
Drop:
ALL
Run As Non Root: true
Run As User: 1000
Seccomp Profile:
Type: RuntimeDefault
Pod Placement Policy:
Name: default
Security Context:
Fs Group: 1000
Replicas: 1
Version: 28.0.1
Zookeeper Ref:
Name: druid-quickstart-zk
Namespace: demo
Version: 3.7.2
Status:
Conditions:
Last Transition Time: 2024-07-16T10:35:14Z
Message: The KubeDB operator has started the provisioning of Druid: demo/druid-quickstart
Observed Generation: 1
Reason: DatabaseProvisioningStartedSuccessfully
Status: True
Type: ProvisioningStarted
Last Transition Time: 2024-07-16T10:36:44Z
Message: Database dependency is ready
Observed Generation: 1
Reason: DatabaseDependencyReady
Status: True
Type: DatabaseDependencyReady
Last Transition Time: 2024-07-16T10:37:21Z
Message: All desired replicas are ready.
Observed Generation: 1
Reason: AllReplicasReady
Status: True
Type: ReplicaReady
Last Transition Time: 2024-07-16T10:37:51Z
Message: The Druid: demo/druid-quickstart is accepting client requests and nodes formed a cluster
Observed Generation: 1
Reason: DatabaseAcceptingConnectionRequest
Status: True
Type: AcceptingConnection
Last Transition Time: 2024-07-16T10:38:33Z
Message: The Druid: demo/druid-quickstart is ready.
Observed Generation: 1
Reason: ReadinessCheckSucceeded
Status: True
Type: Ready
Last Transition Time: 2024-07-16T10:38:33Z
Message: The Druid: demo/druid-quickstart is successfully provisioned.
Observed Generation: 1
Reason: DatabaseSuccessfullyProvisioned
Status: True
Type: Provisioned
Phase: Ready
Events: <none>
KubeDB Operator Generated Resources
On deployment of a Druid CR, the operator creates the following resources:
$ kubectl get all,secret,petset -n demo -l 'app.kubernetes.io/instance=druid-quickstart'
NAME READY STATUS RESTARTS AGE
pod/druid-quickstart-brokers-0 1/1 Running 0 2m4s
pod/druid-quickstart-coordinators-0 1/1 Running 0 2m10s
pod/druid-quickstart-historicals-0 1/1 Running 0 2m8s
pod/druid-quickstart-middlemanagers-0 1/1 Running 0 2m6s
pod/druid-quickstart-routers-0 1/1 Running 0 2m1s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/druid-quickstart-brokers ClusterIP 10.96.28.252 <none> 8082/TCP 2m13s
service/druid-quickstart-coordinators ClusterIP 10.96.52.186 <none> 8081/TCP 2m13s
service/druid-quickstart-pods ClusterIP None <none> 8081/TCP,8090/TCP,8083/TCP,8091/TCP,8082/TCP,8888/TCP 2m13s
service/druid-quickstart-routers LoadBalancer 10.96.134.202 10.86.51.181 8888:32751/TCP 2m13s
NAME TYPE VERSION AGE
appbinding.appcatalog.appscode.com/druid-quickstart kubedb.com/druid 28.0.1 2m1s
NAME TYPE DATA AGE
secret/druid-quickstart-admin-cred kubernetes.io/basic-auth 2 2m13s
NAME AGE
petset.apps.k8s.appscode.com/druid-quickstart-brokers 2m4s
petset.apps.k8s.appscode.com/druid-quickstart-coordinators 2m10s
petset.apps.k8s.appscode.com/druid-quickstart-historicals 2m8s
petset.apps.k8s.appscode.com/druid-quickstart-middlemanagers 2m6s
petset.apps.k8s.appscode.com/druid-quickstart-routers 2m1s
PetSet- In topology mode, the operator may create 4 to 6 petSets (depending on the topology you provide as overlords and routers are optional) with name{Druid-Name}-{Sufix}.Services- For topology mode, a headless service with name{Druid-Name}-{pods}. Other than that, 2 to 4 more services (depending on the specified topology) with name{Druid-Name}-{Sufix}can be created.{Druid-Name}-{brokers}- The primary service which is used to connect the brokers with external clients.{Druid-Name}-{coordinators}- The primary service which is used to connect the coordinators with external clients.{Druid-Name}-{overlords}- The primary service is only created ifspec.topology.overlordsis provided. In the same way, it is used to connect the overlords with external clients.{Druid-Name}-{routers}- Like the previous one, this primary service is only created ifspec.topology.routersis provided. It is used to connect the routers with external clients.
AppBinding- an AppBinding which hold to connect information for the Druid. Like other resources, it is named after the Druid instance.Secrets- A secret is generated for each Druid cluster.{Druid-Name}-{username}-cred- the auth secrets which hold theusernameandpasswordfor the Druid users. Operator generates credentials foradminuser and creates a secret for authentication.
Connect with Druid Database
We will use port forwarding to connect with our routers of the Druid database. Then we will use curl to send HTTP requests to check cluster health to verify that our Druid database is working well. It is also possible to use External-IP to access druid nodes if you make service type of that node as LoadBalancer.
Check the Service Health
Let’s port-forward the port 8888 to local machine:
$ kubectl port-forward -n demo svc/druid-quickstart-routers 8888
Forwarding from 127.0.0.1:8888 -> 8888
Forwarding from [::1]:8888 -> 8888
Now, the Druid cluster is accessible at localhost:8888. Let’s check the Service Health of Routers of the Druid database.
$ curl "http://localhost:8888/status/health"
true
From the retrieved health information above, we can see that our Druid cluster’s status is true, indicating that the service can receive API calls and is healthy. In the same way it possible to check the health of other druid nodes by port-forwarding the appropriate services.
Access the web console
We can also access the web console of Druid database from any browser by port-forwarding the routers in the same way shown in the aforementioned step or directly using the External-IP if the router service type is LoadBalancer.
Now hit the http://localhost:8888 from any browser, and you will be prompted to provide the credential of the druid database. By following the steps discussed below, you can get the credential generated by the KubeDB operator for your Druid database.
Connection information:
Username:
$ kubectl get secret -n demo druid-quickstart-admin-cred -o jsonpath='{.data.username}' | base64 -d adminPassword:
$ kubectl get secret -n demo druid-quickstart-admin-cred -o jsonpath='{.data.password}' | base64 -d LzJtVRX5E8MorFaf
After providing the credentials correctly, you should be able to access the web console like shown below.
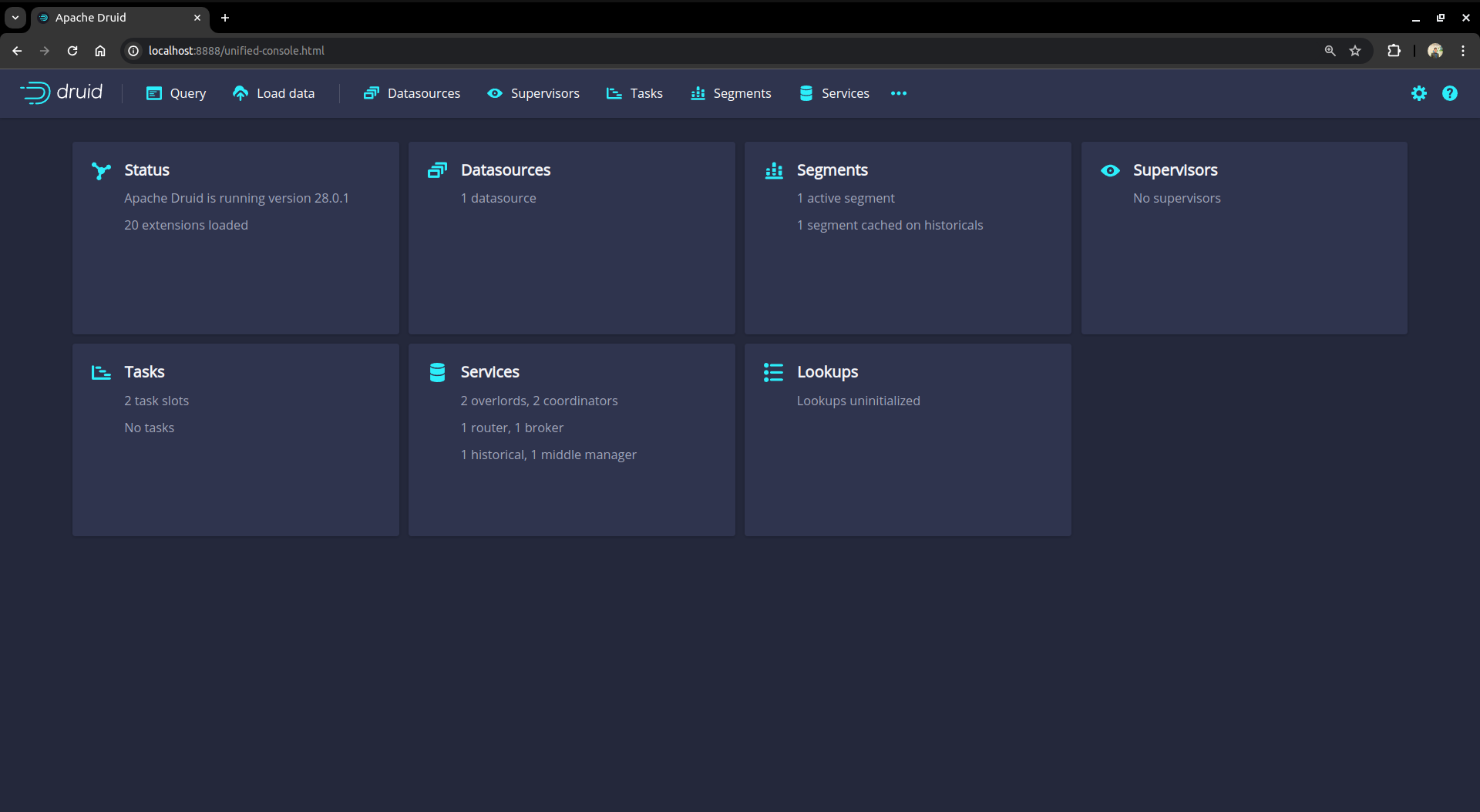
You can use this web console for loading data, managing datasources and tasks, and viewing server status and segment information. You can also run SQL and native Druid queries in the console.
Cleaning up
To clean up the Kubernetes resources created by this tutorial, run:
$ kubectl patch -n demo druid druid-quickstart -p '{"spec":{"deletionPolicy":"WipeOut"}}' --type="merge"
kafka.kubedb.com/druid-quickstart patched
$ kubectl delete dr druid-quickstart -n demo
druid.kubedb.com "druid-quickstart" deleted
$ kubectl delete namespace demo
namespace "demo" deleted
Tips for Testing
If you are just testing some basic functionalities, you might want to avoid additional hassles due to some safety features that are great for the production environment. You can follow these tips to avoid them.
- Use
storageType: Ephemeral. Databases are precious. You might not want to lose your data in your production environment if the database pod fails. So, we recommend to usespec.storageType: Durableand provide storage spec inspec.storagesection. For testing purposes, you can just usespec.storageType: Ephemeral. KubeDB will use emptyDir for storage. You will not require to providespec.storagesection. - Use
deletionPolicy: WipeOut. It is nice to be able to resume the database from the previous one. So, we preserve all yourPVCsand authSecrets. If you don’t want to resume the database, you can just usespec.deletionPolicy: WipeOut. It will clean up every resource that was created with the Druid CR. For more details, please visit here.
Next Steps
- Use kubedb cli to manage databases like kubectl for Kubernetes.
- Want to hack on KubeDB? Check our contribution guidelines.