



































You are looking at the documentation of a prior release. To read the documentation of the latest release, please
visit here.
New to KubeDB? Please start here.
ProxySQL Compute Resource Autoscaling
This guide will give an overview on how KubeDB Autoscaler operator autoscales the database compute resources i.e. cpu and memory using proxysqlautoscaler crd.
Before You Begin
- You should be familiar with the following
KubeDBconcepts:
How Compute Autoscaling Works
The following diagram shows how KubeDB Autoscaler operator autoscales the resources of ProxySQL database components. Open the image in a new tab to see the enlarged version.
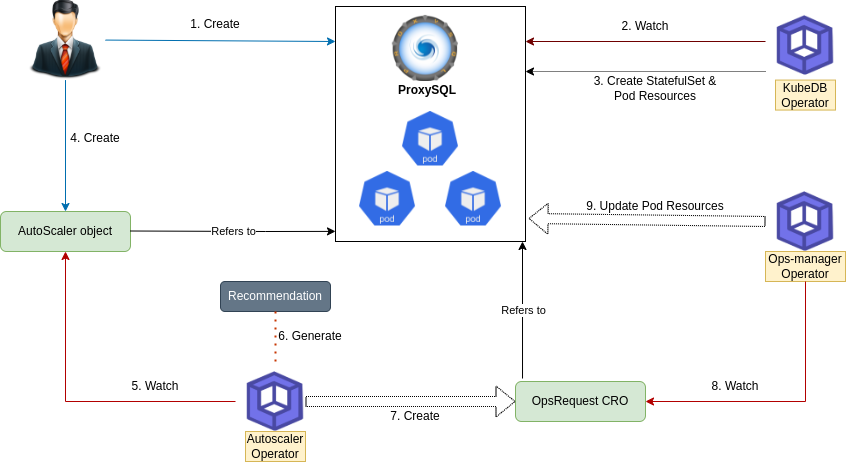
The Auto Scaling process consists of the following steps:
At first, the user creates a
ProxySQLCustom Resource Object (CRO).KubeDBCommunity operator watches theProxySQLCRO.When the operator finds a
ProxySQLCRO, it creates required number ofStatefulSetsand related necessary stuff like secrets, services, etc.Then, in order to set up autoscaling of the CPU & Memory resources of the
ProxySQLdatabase the user creates aProxySQLAutoscalerCRO with desired configuration.KubeDBAutoscaler operator watches theProxySQLAutoscalerCRO.KubeDBAutoscaler operator utilizes the modified version of Kubernetes official VPA-Recommender for different components of the database, as specified in theproxysqlautoscalerCRO. It generates recommendations based on resource usages, & store them in thestatussection of the autoscaler CRO.If the generated recommendation doesn’t match the current resources of the database, then
KubeDBAutoscaler operator creates aProxySQLOpsRequestCRO to scale the database to match the recommendation provided by the VPA object.KubeDB Ops-Manager operatorwatches theProxySQLOpsRequestCRO.Lastly, the
KubeDB Ops-Manager operatorwill scale the database component vertically as specified on theProxySQLOpsRequestCRO.
In the next docs, we are going to show a step by step guide on Autoscaling of ProxySQL database using ProxySQLAutoscaler CRD.