



































You are looking at the documentation of a prior release. To read the documentation of the latest release, please
visit here.
New to KubeDB? Please start here.
Monitoring Druid Using Prometheus operator
Prometheus operator provides simple and Kubernetes native way to deploy and configure Prometheus server. This tutorial will show you how to use Prometheus operator to monitor Druid database deployed with KubeDB.
Before You Begin
At first, you need to have a Kubernetes cluster, and the kubectl command-line tool must be configured to communicate with your cluster. If you do not already have a cluster, you can create one locally by using kind.
To learn how Prometheus monitoring works with KubeDB in general, please visit here.
We need a Prometheus operator instance running. If you don’t already have a running instance, you can deploy one using this helm chart here.
To keep Prometheus resources isolated, we are going to use a separate namespace called
monitoringto deploy the prometheus operator helm chart. Alternatively, you can use--create-namespaceflag while deploying prometheus. We are going to deploy database indemonamespace.$ kubectl create ns monitoring namespace/monitoring created $ kubectl create ns demo namespace/demo created
Note: YAML files used in this tutorial are stored in docs/examples/druid folder in GitHub repository kubedb/docs.
Find out required labels for ServiceMonitor
We need to know the labels used to select ServiceMonitor by a Prometheus crd. We are going to provide these labels in spec.monitor.prometheus.serviceMonitor.labels field of Druid crd so that KubeDB creates ServiceMonitor object accordingly.
At first, let’s find out the available Prometheus server in our cluster.
$ kubectl get prometheus --all-namespaces
NAMESPACE NAME VERSION DESIRED READY RECONCILED AVAILABLE AGE
monitoring prometheus-kube-prometheus-prometheus v2.42.0 1 1 True True 2d23h
If you don’t have any Prometheus server running in your cluster, deploy one following the guide specified in Before You Begin section.
Now, let’s view the YAML of the available Prometheus server prometheus in monitoring namespace.
$ kubectl get prometheus -n monitoring prometheus-kube-prometheus-prometheus -o yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
annotations:
meta.helm.sh/release-name: prometheus
meta.helm.sh/release-namespace: monitoring
creationTimestamp: "2023-03-27T07:56:04Z"
generation: 1
labels:
app: kube-prometheus-stack-prometheus
app.kubernetes.io/instance: prometheus
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/part-of: kube-prometheus-stack
app.kubernetes.io/version: 45.7.1
chart: kube-prometheus-stack-45.7.1
heritage: Helm
release: prometheus
name: prometheus-kube-prometheus-prometheus
namespace: monitoring
resourceVersion: "638797"
uid: 0d1e7b8a-44ae-4794-ab45-95a5d7ae7f91
spec:
alerting:
alertmanagers:
- apiVersion: v2
name: prometheus-kube-prometheus-alertmanager
namespace: monitoring
pathPrefix: /
port: http-web
enableAdminAPI: false
evaluationInterval: 30s
externalUrl: http://prometheus-kube-prometheus-prometheus.monitoring:9090
hostNetwork: false
image: quay.io/prometheus/prometheus:v2.42.0
listenLocal: false
logFormat: logfmt
logLevel: info
paused: false
podMonitorNamespaceSelector: {}
podMonitorSelector:
matchLabels:
release: prometheus
portName: http-web
probeNamespaceSelector: {}
probeSelector:
matchLabels:
release: prometheus
replicas: 1
retention: 10d
routePrefix: /
ruleNamespaceSelector: {}
ruleSelector:
matchLabels:
release: prometheus
scrapeInterval: 30s
securityContext:
fsGroup: 2000
runAsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-kube-prometheus-prometheus
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector:
matchLabels:
release: prometheus
shards: 1
version: v2.42.0
walCompression: true
status:
availableReplicas: 1
conditions:
- lastTransitionTime: "2023-03-27T07:56:23Z"
observedGeneration: 1
status: "True"
type: Available
- lastTransitionTime: "2023-03-30T03:39:18Z"
observedGeneration: 1
status: "True"
type: Reconciled
paused: false
replicas: 1
shardStatuses:
- availableReplicas: 1
replicas: 1
shardID: "0"
unavailableReplicas: 0
updatedReplicas: 1
unavailableReplicas: 0
updatedReplicas: 1
Notice the spec.serviceMonitorSelector section. Here, release: prometheus label is used to select ServiceMonitor crd. So, we are going to use this label in spec.monitor.prometheus.serviceMonitor.labels field of Druid crd.
Deploy Druid with Monitoring Enabled
At first, let’s deploy a Druid database with monitoring enabled. Below is the Druid object that we are going to create.
apiVersion: kubedb.com/v1alpha2
kind: Druid
metadata:
name: druid-with-monitoring
namespace: demo
spec:
version: 28.0.1
deepStorage:
type: s3
configSecret:
name: deep-storage-config
topology:
routers:
replicas: 1
monitor:
agent: prometheus.io/operator
prometheus:
serviceMonitor:
labels:
release: prometheus
interval: 10s
deletionPolicy: WipeOut
Here,
monitor.agent: prometheus.io/operatorindicates that we are going to monitor this server using Prometheus operator.monitor.prometheus.serviceMonitor.labelsspecifies that KubeDB should createServiceMonitorwith these labels.monitor.prometheus.intervalindicates that the Prometheus server should scrape metrics from this database with 10 seconds interval.
Let’s create the druid object that we have shown above,
$ kubectl create -f https://github.com/kubedb/docs/raw/v2024.9.30/docs/examples/druid/monitoring/yamls/druid-with-monirtoring.yaml
druids.kubedb.com/druid-with-monitoring created
Now, wait for the database to go into Running state.
$ kubectl get dr -n demo druid
NAME TYPE VERSION STATUS AGE
druid-with-monitoring kubedb.com/v1alpha2 3.6.1 Ready 2m24s
KubeDB will create a separate stats service with name {Druid crd name}-stats for monitoring purpose.
$ kubectl get svc -n demo --selector="app.kubernetes.io/instance=druid-with-monitoring"
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
druid-with-monitoring-brokers ClusterIP 10.96.28.252 <none> 8082/TCP 2m13s
druid-with-monitoring-coordinators ClusterIP 10.96.52.186 <none> 8081/TCP 2m13s
druid-with-monitoring-pods ClusterIP None <none> 8081/TCP,8090/TCP,8083/TCP,8091/TCP,8082/TCP,8888/TCP 2m13s
druid-with-monitoring-routers ClusterIP 10.96.134.202 <none> 8888/TCP 2m13s
druid-with-monitoring-stats ClusterIP 10.96.222.96 <none> 56790/TCP 2m13s
Here, druid-with-monitoring-stats service has been created for monitoring purpose.
Let’s describe this stats service.
$ kubectl describe svc -n demo druid-with-monitoring-stats
Name: druid-with-monitoring-stats
Namespace: demo
Labels: app.kubernetes.io/component=database
app.kubernetes.io/instance=druid-with-monitoring
app.kubernetes.io/managed-by=kubedb.com
app.kubernetes.io/name=druids.kubedb.com
kubedb.com/role=stats
Annotations: monitoring.appscode.com/agent: prometheus.io/operator
Selector: app.kubernetes.io/instance=druid-with-monitoring,app.kubernetes.io/managed-by=kubedb.com,app.kubernetes.io/name=druids.kubedb.com
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.96.29.174
IPs: 10.96.29.174
Port: metrics 9104/TCP
TargetPort: metrics/TCP
Endpoints: 10.244.0.68:9104,10.244.0.71:9104,10.244.0.72:9104 + 2 more...
Session Affinity: None
Events: <none>
Notice the Labels and Port fields. ServiceMonitor will use this information to target its endpoints.
KubeDB will also create a ServiceMonitor crd in demo namespace that select the endpoints of druid-with-monitoring-stats service. Verify that the ServiceMonitor crd has been created.
$ kubectl get servicemonitor -n demo
NAME AGE
druid-with-monitoring-stats 4m49s
Let’s verify that the ServiceMonitor has the label that we had specified in spec.monitor section of Druid crd.
$ kubectl get servicemonitor -n demo druid-with-monitoring-stats -o yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
creationTimestamp: "2024-11-01T10:25:14Z"
generation: 1
labels:
app.kubernetes.io/component: database
app.kubernetes.io/instance: druid-with-monitoring
app.kubernetes.io/managed-by: kubedb.com
app.kubernetes.io/name: druids.kubedb.com
release: prometheus
name: druid-with-monitoring-stats
namespace: demo
ownerReferences:
- apiVersion: v1
blockOwnerDeletion: true
controller: true
kind: Service
name: druid-with-monitoring-stats
uid: b3ae48f3-476e-4cec-95f6-f8e28538b605
resourceVersion: "597152"
uid: ff385538-eba5-48a3-91c1-1a4b15f3018a
spec:
endpoints:
- honorLabels: true
interval: 10s
path: /metrics
port: metrics
namespaceSelector:
matchNames:
- demo
selector:
matchLabels:
app.kubernetes.io/component: database
app.kubernetes.io/instance: druid-with-monitoring
app.kubernetes.io/managed-by: kubedb.com
app.kubernetes.io/name: druids.kubedb.com
kubedb.com/role: stats
Notice that the ServiceMonitor has label release: prometheus that we had specified in Druid crd.
Also notice that the ServiceMonitor has selector which match the labels we have seen in the druid-with-monitoring-stats service. It also, target the metrics port that we have seen in the stats service.
Verify Monitoring Metrics
At first, let’s find out the respective Prometheus pod for prometheus Prometheus server.
$ kubectl get pod -n monitoring -l=app.kubernetes.io/name=prometheus
NAME READY STATUS RESTARTS AGE
prometheus-prometheus-kube-prometheus-prometheus-0 2/2 Running 8 (4h27m ago) 3d
Prometheus server is listening to port 9090 of prometheus-prometheus-kube-prometheus-prometheus-0 pod. We are going to use port forwarding to access Prometheus dashboard.
Run following command on a separate terminal to forward the port 9090 of prometheus-kube-prometheus-prometheus service which is pointing to the prometheus pod,
$ kubectl port-forward -n monitoring svc/prometheus-kube-prometheus-prometheus 9090
Forwarding from 127.0.0.1:9090 -> 9090
Forwarding from [::1]:9090 -> 9090
Now, we can access the dashboard at localhost:9090. Open http://localhost:9090 in your browser. You should see metrics endpoint of druid-with-monitoring-stats service as one of the targets.
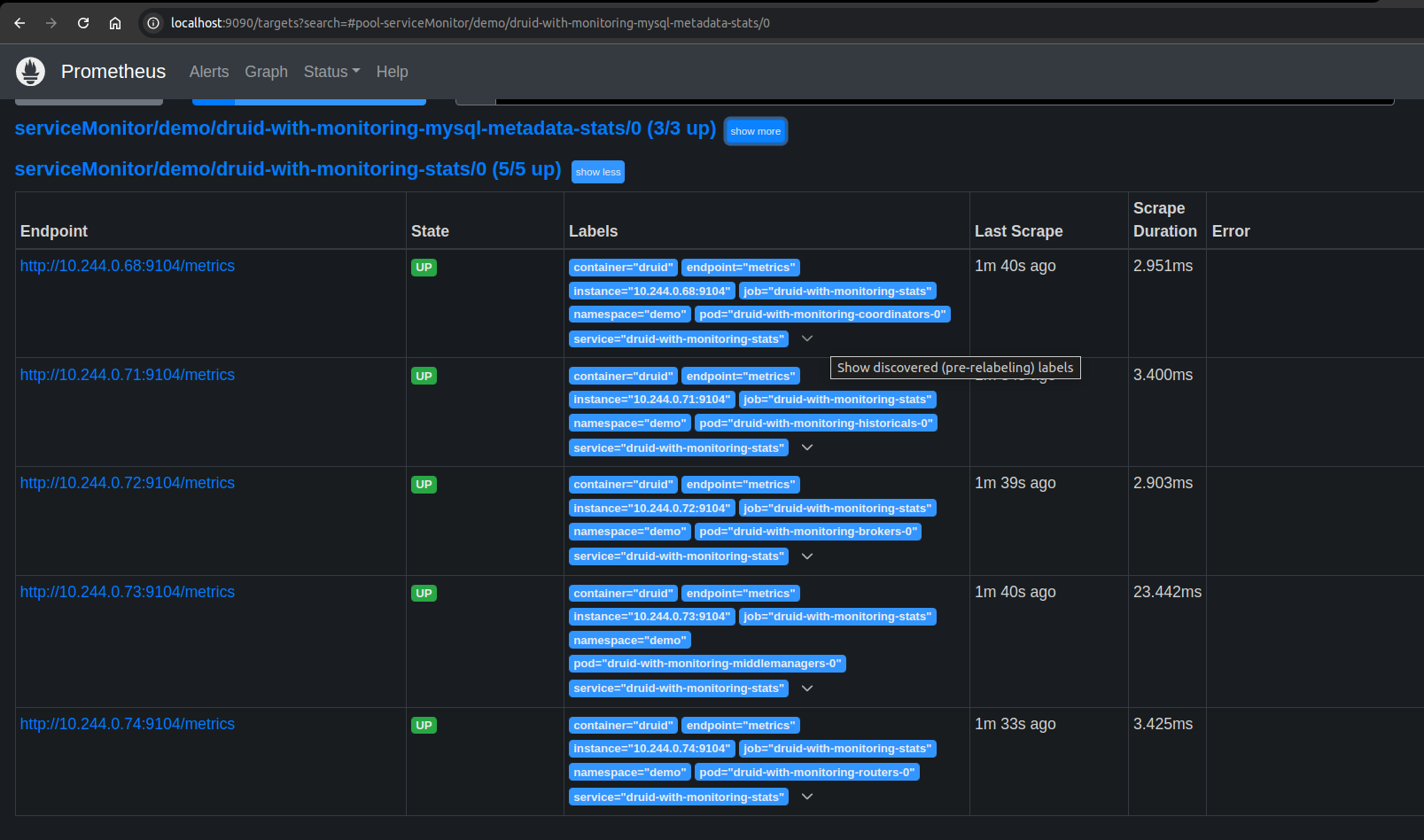
Check the endpoint and service labels. It verifies that the target is our expected database. Now, you can view the collected metrics and create a graph from homepage of this Prometheus dashboard. You can also use this Prometheus server as data source for Grafana and create a beautiful dashboard with collected metrics.
Cleaning up
To clean up the Kubernetes resources created by this tutorial, run following commands
kubectl delete -n demo dr/druid-with-monitoring
kubectl delete ns demo
Next Steps
- Learn how to use KubeDB to run Apache Druid cluster here.
- Deploy dedicated cluster for Apache Druid [//]: # (- Deploy [combined cluster](/docs/guides/druid/clustering/combined-cluster/index.md) for Apache Druid)
- Detail concepts of DruidVersion object. [//]: # (- Learn to use KubeDB managed Druid objects using [CLIs](/docs/guides/druid/cli/cli.md).)
- Want to hack on KubeDB? Check our contribution guidelines.