



































You are looking at the documentation of a prior release. To read the documentation of the latest release, please
visit here.
New to KubeDB? Please start here.
SingleStore Cluster
Here we’ll discuss some concepts about SingleStore Cluster.
what is SingleStore Cluster
A SingleStore cluster is a distributed database system that consists of multiple servers (nodes) working together to provide high performance, scalability, and fault tolerance for data storage and processing. It is specifically designed to handle both transactional (OLTP) and analytical (OLAP) workloads, making it suitable for a wide range of real-time data use cases. Here’s a detailed look at what a SingleStore cluster is and how it functions:
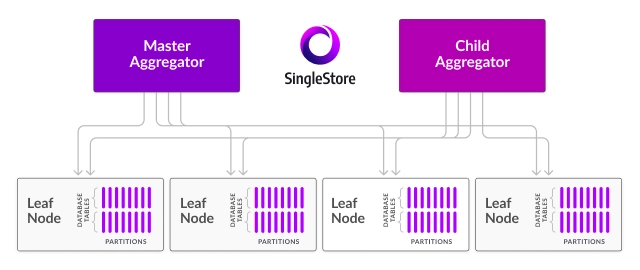
Components of a SingleStore Cluster
A SingleStore cluster is made up of two main types of nodes:
Aggregators:
- Purpose: These nodes act as query routers. Aggregators handle query parsing, optimization, and distribution to the other nodes in the cluster. They do not store data themselves.
- Role: Aggregators receive SQL queries, optimize them, and then route them to the appropriate leaf nodes that actually store and process the data.
- Benefits: They help balance the workload and ensure that queries are efficiently executed by leveraging the full processing power of the cluster.
Leaves:
- Purpose: These are the nodes responsible for data storage and processing. They store data in distributed partitions called shards.
- Role: Leaf nodes are responsible for executing the actual query tasks. They perform data retrieval, computation, and provide results back to the aggregators.
- Benefits: Leaf nodes ensure that data is distributed across the cluster, enabling horizontal scalability and high fault tolerance.
How a SingleStore Cluster Works
Data Sharding and Partitioning:
- In a SingleStore cluster, data is partitioned into
shardsthat are distributed across multiple leaf nodes. Each shard is a portion of the overall dataset, and the distribution allows the workload to be spread evenly, improving both read and write performance. - Sharding also allows for
parallel processing, which enhances query performance by splitting tasks among several nodes.
- In a SingleStore cluster, data is partitioned into
Scalability:
- SingleStore clusters can be
scaled horizontallyby adding more nodes (both leaf and aggregator). As data volume grows, adding more leaf nodes allows the system to continue performing efficiently without the need for massive hardware upgrades. - Aggregator nodes can also be scaled to handle more queries concurrently, helping balance the load during times of high user activity.
- SingleStore clusters can be
High Availability and Fault Tolerance:
- SingleStore clusters maintain multiple replicas of each shard on different leaf nodes. This replication provides
high availability (HA)because if one node fails, another node holding a replica can take over, ensuring no data loss and minimizing downtime. - The automatic failover and
self-healingcapabilities ensure that the system continues to operate smoothly even in the face of hardware or software failures.
- SingleStore clusters maintain multiple replicas of each shard on different leaf nodes. This replication provides
Distributed Query Processing:
- When a query is submitted to an aggregator, it breaks down the query into smaller tasks and sends them to relevant leaf nodes.
Parallel processingat the leaf nodes enables quick handling of large, complex queries, making it particularly effective for real-time analytics.
Hybrid Workload Handling:
- SingleStore is a
unified database, meaning it can handleboth OLTP (Online Transaction Processing)andOLAP (Online Analytical Processing)workloads within the same cluster. - This capability is achieved by storing data in rowstore for fast transactions and
columnstorefor efficient analytical queries, which can be leveraged simultaneously.
- SingleStore is a
Key Features of a SingleStore Cluster
- Elastic Scaling: Nodes can be added or removed without significant downtime, allowing the system to adjust to changing workload requirements.
- In-Memory Storage: Data can be stored in memory to enhance processing speed, particularly useful for applications requiring real-time performance.
- Cloud Integration: SingleStore clusters are designed to work well in cloud environments, supporting deployments on cloud infrastructure or container orchestration platforms like
Kubernetes.
Use Cases
- Real-Time Analytics: The combination of in-memory processing and distributed architecture allows SingleStore clusters to handle real-time analytical queries over large datasets, which is valuable in industries like finance, retail, and IoT.
- Mixed Workloads: SingleStore can handle simultaneous read-heavy analytics and write-heavy transactional workloads, making it a good choice for applications that need both low-latency transactions and in-depth data analysis.
- Data Warehousing: The ability to process large volumes of data quickly also makes SingleStore suitable for
modern data warehousing, where performance is crucial for handling big data operations.
Benefits of SingleStore Clusters
- High Throughput: The distributed nature allows the system to support high data ingestion rates and large-scale analytical processing.
- Fault Tolerance: With multiple replicas of each shard, SingleStore clusters provide redundancy, helping to ensure that data is not lost and the system remains available.
- Simplified Management: SingleStore offers tools that simplify the management of clusters, including auto-failover and data rebalancing.
Limitations
- Resource Overhead: Running a distributed cluster comes with extra costs in terms of hardware or cloud resources, especially due to the need for replication.
- Complexity in Management: Managing a large cluster, particularly in hybrid cloud or on-prem environments, can become complex and requires knowledge of distributed systems.
- Network Dependency: The cluster performance relies heavily on the network, and any issues with network latency or bandwidth can impact overall efficiency.
Next Steps
- Deploy SingleStore Cluster using KubeDB.