



































You are looking at the documentation of a prior release. To read the documentation of the latest release, please
visit here.
New to KubeDB? Please start here.
Druid Vertical Scaling
This guide will give an overview on how KubeDB Ops-manager operator updates the resources(for example CPU and Memory etc.) of the Druid.
Before You Begin
- You should be familiar with the following
KubeDBconcepts:
How Vertical Scaling Process Works
The following diagram shows how KubeDB Ops-manager operator updates the resources of the Druid. Open the image in a new tab to see the enlarged version.
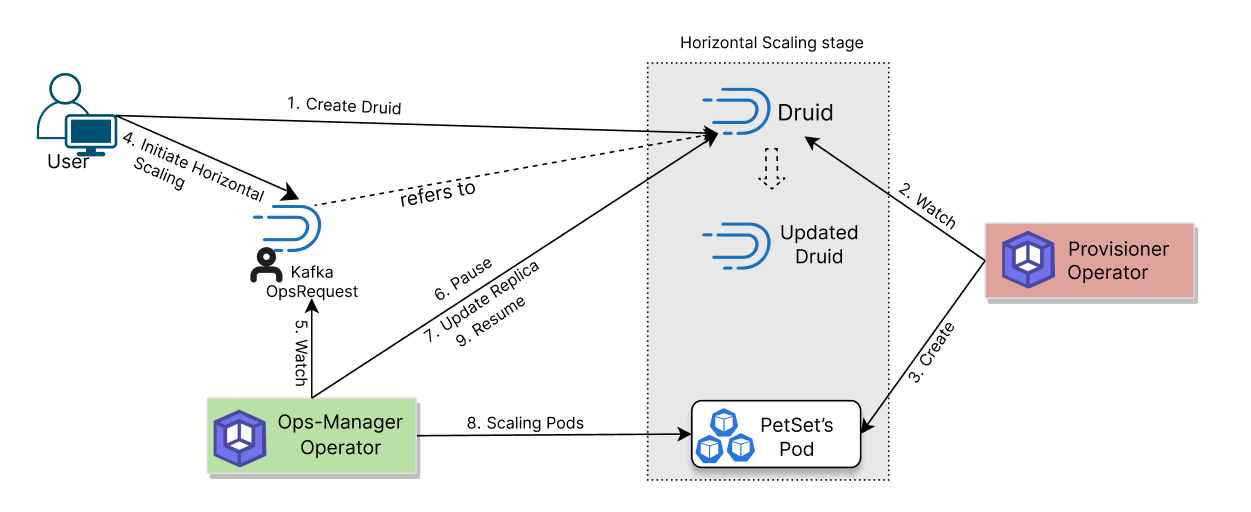
The vertical scaling process consists of the following steps:
At first, a user creates a
DruidCustom Resource (CR).KubeDBProvisioner operator watches theDruidCR.When the operator finds a
DruidCR, it creates required number ofPetSetsand related necessary stuff like secrets, services, etc.Then, in order to update the resources(for example
CPU,Memoryetc.) of theDruidcluster, the user creates aDruidOpsRequestCR with desired information.KubeDBOps-manager operator watches theDruidOpsRequestCR.When it finds a
DruidOpsRequestCR, it halts theDruidobject which is referred from theDruidOpsRequest. So, theKubeDBProvisioner operator doesn’t perform any operations on theDruidobject during the vertical scaling process.Then the
KubeDBOps-manager operator will update resources of the PetSet Pods to reach desired state.After the successful update of the resources of the PetSet’s replica, the
KubeDBOps-manager operator updates theDruidobject to reflect the updated state.After the successful update of the
Druidresources, theKubeDBOps-manager operator resumes theDruidobject so that theKubeDBProvisioner operator resumes its usual operations.
In the next docs, we are going to show a step by step guide on updating resources of Druid database using DruidOpsRequest CRD.