
































You are looking at the documentation of a prior release. To read the documentation of the latest release, please
visit here.
New to KubeDB? Please start here.
ConnectCluster QuickStart
This tutorial will show you how to use KubeDB to run an Apache Kafka Connect Cluster.
Before You Begin
At first, you need to have a Kubernetes cluster, and the kubectl command-line tool must be configured to communicate with your cluster. If you do not already have a cluster, you can create one by using kind.
Now, install the KubeDB operator in your cluster following the steps here.
To keep things isolated, this tutorial uses a separate namespace called demo throughout this tutorial.
$ kubectl create namespace demo
namespace/demo created
$ kubectl get namespace
NAME STATUS AGE
demo Active 9s
Note: YAML files used in this tutorial are stored in guides/kafka/quickstart/overview/connectcluster/yamls folder in GitHub repository kubedb/docs.
We have designed this tutorial to demonstrate a production setup of KubeDB managed Apache Kafka Connect Cluster. If you just want to try out KubeDB, you can bypass some safety features following the tips here.
Find Available ConnectCluster Versions
When you install the KubeDB operator, it registers a CRD named KafkaVersion. ConnectCluster Version is using the KafkaVersion CR to define the specification of ConnectCluster. The installation process comes with a set of tested KafkaVersion objects. Let’s check available KafkaVersions by,
$ kubectl get kfversion
NAME VERSION DB_IMAGE DEPRECATED AGE
3.3.2 3.3.2 ghcr.io/appscode-images/kafka-kraft:3.3.2 24m
3.4.1 3.4.1 ghcr.io/appscode-images/kafka-kraft:3.4.1 24m
3.5.1 3.5.1 ghcr.io/appscode-images/kafka-kraft:3.5.1 24m
3.5.2 3.5.2 ghcr.io/appscode-images/kafka-kraft:3.5.2 24m
3.6.0 3.6.0 ghcr.io/appscode-images/kafka-kraft:3.6.0 24m
3.6.1 3.6.1 ghcr.io/appscode-images/kafka-kraft:3.6.1 24m
Notice the DEPRECATED column. Here, true means that this KafkaVersion is deprecated for the current KubeDB version. KubeDB will not work for deprecated KafkaVersion. You can also use the short from kfversion to check available KafkaVersions.
In this tutorial, we will use 3.6.1 KafkaVersion CR to create a Kafka Connect cluster.
Find Available KafkaConnector Versions
When you install the KubeDB operator, it registers a CRD named KafkaConnectorVersion. KafkaConnectorVersion use to load connector-plugins to run ConnectCluster worker node(ex. mongodb-source/sink). The installation process comes with a set of tested KafkaConnectorVersion objects. Let’s check available KafkaConnectorVersions by,
$ kubectl get kcversion
NAME VERSION CONNECTOR_IMAGE DEPRECATED AGE
gcs-0.13.0 0.13.0 ghcr.io/appscode-images/kafka-connector-gcs:0.13.0 10m
jdbc-2.6.1.final 2.6.1 ghcr.io/appscode-images/kafka-connector-jdbc:2.6.1.final 10m
mongodb-1.11.0 1.11.0 ghcr.io/appscode-images/kafka-connector-mongodb:1.11.0 10m
mysql-2.4.2.final 2.4.2 ghcr.io/appscode-images/kafka-connector-mysql:2.4.2.final 10m
postgres-2.4.2.final 2.4.2 ghcr.io/appscode-images/kafka-connector-postgres:2.4.2.final 10m
s3-2.15.0 2.15.0 ghcr.io/appscode-images/kafka-connector-s3:2.15.0 10m
Notice the DEPRECATED column. Here, true means that this KafkaConnectorVersion is deprecated for the current KubeDB version. KubeDB will not work for deprecated KafkaConnectorVersion. You can also use the short from kcversion to check available KafkaConnectorVersions.
Details of ConnectorPlugins
| Connector Plugin | Type | Version | Connector Class |
|---|---|---|---|
| mongodb-1.11.0 | Source | 1.11.0 | com.mongodb.kafka.connect.MongoSourceConnector |
| mongodb-1.11.0 | Sink | 1.11.0 | com.mongodb.kafka.connect.MongoSinkConnector |
| mysql-2.4.2.final | Source | 2.4.2.Final | io.debezium.connector.mysql.MySqlConnector |
| postgres-2.4.2.final | Source | 2.4.2.Final | io.debezium.connector.postgresql.PostgresConnector |
| jdbc-2.6.1.final | Sink | 2.6.1.Final | io.debezium.connector.jdbc.JdbcSinkConnector |
| s3-2.15.0 | Sink | 2.15.0 | io.aiven.kafka.connect.s3.AivenKafkaConnectS3SinkConnector |
| gcs-0.13.0 | Sink | 0.13.0 | io.aiven.kafka.connect.gcs.GcsSinkConnector |
Create a Kafka Connect Cluster
The KubeDB operator implements a ConnectCluster CRD to define the specification of ConnectCluster.
The ConnectCluster instance used for this tutorial:
apiVersion: kafka.kubedb.com/v1alpha1
kind: ConnectCluster
metadata:
name: connectcluster-quickstart
namespace: demo
spec:
version: 3.6.1
replicas: 3
connectorPlugins:
- mongodb-1.11.0
- mysql-2.4.2.final
- postgres-2.4.2.final
- jdbc-2.6.1.final
kafkaRef:
name: kafka-quickstart
namespace: demo
terminationPolicy: WipeOut
Here,
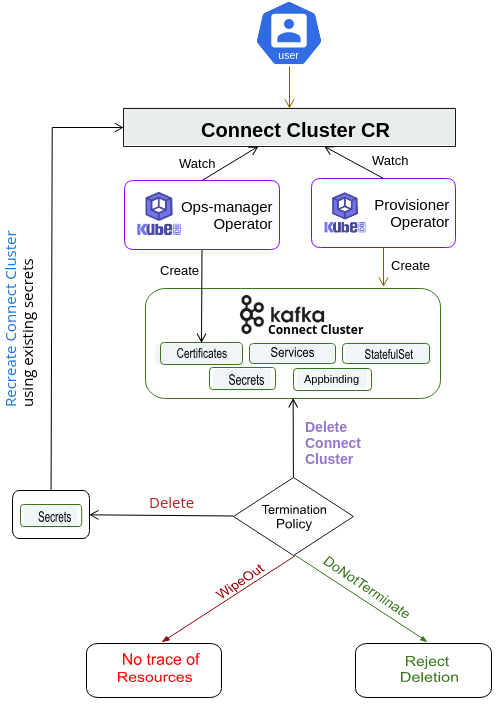
spec.version- is the name of the KafkaVersion CR. Here, a ConnectCluster of version3.6.1will be created.spec.replicas- specifies the number of ConnectCluster workers.spec.connectorPlugins- is the name of the KafkaConnectorVersion CR. Here, mongodb, mysql, postgres, and jdbc connector-plugins will be loaded to the ConnectCluster worker nodes.spec.kafkaRefspecifies the Kafka instance that the ConnectCluster will connect to. Here, the ConnectCluster will connect to the Kafka instance namedkafka-quickstartin thedemonamespace.spec.terminationPolicyspecifies what KubeDB should do when a user try to delete ConnectCluster CR. Termination policyWipeOutwill delete the worker pods, secret when the ConnectCluster CR is deleted.
N.B:
- If replicas are set to 1, the ConnectCluster will run in standalone mode, you can’t scale replica after provision the cluster.
- If replicas are set to more than 1, the ConnectCluster will run in distributed mode.
- If you want to run the ConnectCluster in distributed mode with 1 replica, you must set the
CONNECT_CLUSTER_MODEenvironment variable todistributedin the pod template.
spec:
podTemplate:
spec:
containers:
- name: connect-cluster
env:
- name: CONNECT_CLUSTER_MODE
value: distributed
Before create ConnectCluster, you have to deploy a Kafka cluster first. To deploy kafka cluster, follow the Kafka Quickstart guide. Let’s assume kafka-quickstart is already deployed using KubeDB.
Let’s create the ConnectCluster CR that is shown above:
$ kubectl apply -f https://github.com/kubedb/docs/raw/v2024.4.27/docs/guides/kafka/quickstart/overview/connectcluster/yamls/connectcluster.yaml
connectcluster.kafka.kubedb.com/connectcluster-quickstart created
The ConnectCluster’s STATUS will go from Provisioning to Ready state within few minutes. Once the STATUS is Ready, you are ready to use the ConnectCluster.
$ kubectl get connectcluster -n demo -w
NAME TYPE VERSION STATUS AGE
connectcluster-quickstart kafka.kubedb.com/v1alpha1 3.6.1 Provisioning 2s
connectcluster-quickstart kafka.kubedb.com/v1alpha1 3.6.1 Provisioning 4s
.
.
connectcluster-quickstart kafka.kubedb.com/v1alpha1 3.6.1 Ready 112s
Describe the ConnectCluster object to observe the progress if something goes wrong or the status is not changing for a long period of time:
$ kubectl describe connectcluster -n demo connectcluster-quickstart
Name: connectcluster-quickstart
Namespace: demo
Labels: <none>
Annotations: <none>
API Version: kafka.kubedb.com/v1alpha1
Kind: ConnectCluster
Metadata:
Creation Timestamp: 2024-05-02T07:06:07Z
Finalizers:
kafka.kubedb.com/finalizer
Generation: 2
Resource Version: 8824
UID: bbf4669c-db7a-46c0-a1f4-c93a5e24592e
Spec:
Auth Secret:
Name: connectcluster-quickstart-connect-cred
Connector Plugins:
mongodb-1.11.0
mysql-2.4.2.final
postgres-2.4.2.final
jdbc-2.6.1.final
Health Checker:
Failure Threshold: 3
Period Seconds: 20
Timeout Seconds: 10
Kafka Ref:
Name: kafka-quickstart
Namespace: demo
Pod Template:
Controller:
Metadata:
Spec:
Containers:
Env:
Name: CONNECT_CLUSTER_MODE
Value: distributed
Name: connect-cluster
Resources:
Limits:
Memory: 1Gi
Requests:
Cpu: 500m
Memory: 1Gi
Security Context:
Allow Privilege Escalation: false
Capabilities:
Drop:
ALL
Run As Group: 1001
Run As Non Root: true
Run As User: 1001
Seccomp Profile:
Type: RuntimeDefault
Init Containers:
Name: mongodb
Resources:
Limits:
Memory: 512Mi
Requests:
Cpu: 200m
Memory: 512Mi
Security Context:
Allow Privilege Escalation: false
Capabilities:
Drop:
ALL
Run As Group: 1001
Run As Non Root: true
Run As User: 1001
Seccomp Profile:
Type: RuntimeDefault
Name: mysql
Resources:
Limits:
Memory: 512Mi
Requests:
Cpu: 200m
Memory: 512Mi
Security Context:
Allow Privilege Escalation: false
Capabilities:
Drop:
ALL
Run As Group: 1001
Run As Non Root: true
Run As User: 1001
Seccomp Profile:
Type: RuntimeDefault
Name: postgres
Resources:
Limits:
Memory: 512Mi
Requests:
Cpu: 200m
Memory: 512Mi
Security Context:
Allow Privilege Escalation: false
Capabilities:
Drop:
ALL
Run As Group: 1001
Run As Non Root: true
Run As User: 1001
Seccomp Profile:
Type: RuntimeDefault
Name: jdbc
Resources:
Limits:
Memory: 512Mi
Requests:
Cpu: 200m
Memory: 512Mi
Security Context:
Allow Privilege Escalation: false
Capabilities:
Drop:
ALL
Run As Group: 1001
Run As Non Root: true
Run As User: 1001
Seccomp Profile:
Type: RuntimeDefault
Security Context:
Fs Group: 1001
Replicas: 3
Termination Policy: WipeOut
Version: 3.6.1
Status:
Conditions:
Last Transition Time: 2024-05-02T08:04:29Z
Message: The KubeDB operator has started the provisioning of ConnectCluster: demo/connectcluster-quickstart
Observed Generation: 1
Reason: DatabaseProvisioningStartedSuccessfully
Status: True
Type: ProvisioningStarted
Last Transition Time: 2024-05-02T08:06:20Z
Message: All desired replicas are ready.
Observed Generation: 2
Reason: AllReplicasReady
Status: True
Type: ReplicaReady
Last Transition Time: 2024-05-02T08:06:45Z
Message: The ConnectCluster: demo/connectcluster-quickstart is accepting client requests
Observed Generation: 2
Reason: DatabaseAcceptingConnectionRequest
Status: True
Type: AcceptingConnection
Last Transition Time: 2024-05-02T08:06:45Z
Message: The ConnectCluster: demo/connectcluster-quickstart is ready.
Observed Generation: 2
Reason: ReadinessCheckSucceeded
Status: True
Type: Ready
Last Transition Time: 2024-05-02T08:06:46Z
Message: The ConnectCluster: demo/connectcluster-quickstart is successfully provisioned.
Observed Generation: 2
Reason: DatabaseSuccessfullyProvisioned
Status: True
Type: Provisioned
Phase: Ready
Events: <none>
KubeDB Operator Generated Resources
On deployment of a ConnectCluster CR, the operator creates the following resources:
$ kubectl get all,secret -n demo -l 'app.kubernetes.io/instance=connectcluster-quickstart'
NAME READY STATUS RESTARTS AGE
pod/connectcluster-quickstart-0 1/1 Running 0 3m50s
pod/connectcluster-quickstart-1 1/1 Running 0 3m7s
pod/connectcluster-quickstart-2 1/1 Running 0 2m36s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/connectcluster-quickstart ClusterIP 10.128.221.44 <none> 8083/TCP 3m55s
service/connectcluster-quickstart-pods ClusterIP None <none> 8083/TCP 3m55s
NAME READY AGE
statefulset.apps/connectcluster-quickstart 3/3 3m50s
NAME TYPE VERSION AGE
appbinding.appcatalog.appscode.com/connectcluster-quickstart kafka.kubedb.com/connectcluster 3.6.1 3m50s
NAME TYPE DATA AGE
secret/connectcluster-quickstart-config Opaque 1 3m55s
secret/connectcluster-quickstart-connect-cred kubernetes.io/basic-auth 2 3m56s
StatefulSet- a StatefulSet named after the ConnectCluster instance.Services- For a ConnectCluster instance headless service is created with name{ConnectCluster-name}-{pods}and a primary service created with name{ConnectCluster-name}.AppBinding- an AppBinding which hold to connect information for the ConnectCluster worker nodes. It is also named after the ConnectCluster instance.Secrets- 3 types of secrets are generated for each Connect cluster.{ConnectCluster-Name}-connect-cred- the auth secrets which hold theusernameandpasswordfor the Kafka users. Operator generates credentials foradminuser if not provided and creates a secret for authentication.{ConnectCluster-Name}-{alias}-cert- the certificate secrets which holdtls.crt,tls.key, andca.crtfor configuring the ConnectCluster instance if tls enabled.{ConnectCluster-Name}-config- the default configuration secret created by the operator.
Create Connectors
To create a connector, you can use the Kafka Connect REST API. But, KubeDB operator implements a Connector CRD to define the specification of a connector. Create a Connector CR to create a connector. Details of the Connector CR.
At first, we will create config.properties file containing required configuration settings. I am using the mongodb-source connector here. You can use any other connector as per your requirement.
$ cat config.properties
connector.class=com.mongodb.kafka.connect.MongoSourceConnector
tasks.max=1
connection.uri=mongodb://root:[email protected]:27017/
topic.prefix=mongo
database=mongodb
collection=source
poll.max.batch.size=1000
poll.await.time.ms=5000
heartbeat.interval.ms=3000
offset.partition.name=mongo-source
startup.mode=copy_existing
publish.full.document.only=true
key.ignore=true
value.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=false
Here,
- A MongoDB instance is already running. You can use your own MongoDB instance. To run mongodb instance, follow the MongoDB Quickstart guide.
- Update
connection.uriwith your MongoDB URI. Example:mongodb://<username>:<password@<host>:<port>/. - Update
databaseandcollectionas per your MongoDB database and collection name. We are usingmongodbandsourceas database and collection name respectively. - Update
topic.prefixwith your topic prefix. We are usingmongoas topic prefix. So, the topic name will bemongo.mongodb.source.
Now, we will create secret containing config.properties file.
$ kubectl create secret generic mongodb-source-config --from-file=./config.properties -n demo
Now, we will use this secret to create a Connector CR.
apiVersion: kafka.kubedb.com/v1alpha1
kind: Connector
metadata:
name: mongodb-source-connector
namespace: demo
spec:
configSecret:
name: mongodb-source-config
connectClusterRef:
name: connectcluster-quickstart
namespace: demo
terminationPolicy: WipeOut
Here,
spec.configSecret- is the name of the secret containing the connector configuration.spec.connectClusterRef- is the name of the ConnectCluster instance that the connector will run on. This is an appbinding reference of the ConnectCluster instance.spec.terminationPolicy- specifies what KubeDB should do when a user try to delete Connector CR. Termination policyWipeOutwill delete the connector from the ConnectCluster when the Connector CR is deleted. If you want to keep the connector after deleting the Connector CR, you can set the termination policy toDelete.
Now, create the Connector CR that is shown above:
$ kubectl apply -f https://github.com/kubedb/docs/raw/v2024.4.27/docs/guides/kafka/quickstart/overview/connectcluster/yamls/mongodb-source-connector.yaml
connector.kafka.kubedb.com/mongodb-source-connector created
$ kubectl get connector -n demo -w
NAME TYPE CONNECTCLUSTER STATUS AGE
mongodb-source-connector kafka.kubedb.com/v1alpha1 connectcluster-quickstart Pending 0s
mongodb-source-connector kafka.kubedb.com/v1alpha1 connectcluster-quickstart Pending 0s
.
.
mongodb-source-connector kafka.kubedb.com/v1alpha1 connectcluster-quickstart Running 1s
MongoDB source connector is created successfully and the status is Running. Now, the connector is ready to fetch data from the MongoDB instance to the Kafka topic.
Insert Data to MongoDB
Now, we will insert some data to the source collection of the mongodb database. The data will be fetched by the MongoDB source connector and will be published to the Kafka topic.
To insert data to the MongoDB collection, exec into the primary pod of the MongoDB instance and insert data.
mongodb@mg-rep-0:/$ mongo --username root --password XbCj85wKfCPKapJ8 --host mg-rep.demo.svc --port 27017
MongoDB shell version v4.4.26
connecting to: mongodb://mg-rep.demo.svc:27017/?compressors=disabled&gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("b1df7173-d32b-490a-b4c0-4e7d63539dc0") }
MongoDB server version: 4.4.26
rs1:PRIMARY> use mongodb
switched to db mongodb
rs1:PRIMARY> db.source.insertOne({"hi":"kubedb"})
{
"acknowledged" : true,
"insertedId" : ObjectId("66389ca8c43abff3a434b916")
}
rs1:PRIMARY> db.source.insertOne({"kafka":"connectcluster"})
{
"acknowledged" : true,
"insertedId" : ObjectId("66389cb4c43abff3a434b917")
}
rs1:PRIMARY> db.source.insertOne({"mongodb":"source"})
{
"acknowledged" : true,
"insertedId" : ObjectId("66389cc0c43abff3a434b918")
}
Check Data in Kafka Topic
Exec into one of the kafka brokers in interactive mode. Run consumer command to check the data in the topic.
$ kubectl exec -it kafka-quickstart-1 -n demo -- bash
kafka@kafka-quickstart-1:~$ kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer.config config/clientauth.properties --topic mongo.mongodb.source --from-beginning
"{\"_id\": {\"$oid\": \"66389ca8c43abff3a434b916\"}, \"hi\": \"kubedb\"}"
"{\"_id\": {\"$oid\": \"66389cb4c43abff3a434b917\"}, \"kafka\": \"connectcluster\"}"
"{\"_id\": {\"$oid\": \"66389cc0c43abff3a434b918\"}, \"mongodb\": \"source\"}"
You can see the data inserted in the MongoDB collection is fetched by the MongoDB source connector and published to the Kafka topic.
Cleaning up
To clean up the Kubernetes resources created by this tutorial, run:
$ kubectl patch -n demo connectcluster connectcluster-quickstart -p '{"spec":{"terminationPolicy":"WipeOut"}}' --type="merge"
connectcluster.kafka.kubedb.com/connectcluster-quickstart patched
$ kubectl delete kf connectcluster-quickstart -n demo
connectcluster.kafka.kubedb.com "connectcluster-quickstart" deleted
$ kubectl delete namespace demo
namespace "demo" deleted
Tips for Testing
If you are just testing some basic functionalities, you might want to avoid additional hassles due to some safety features that are great for the production environment. You can follow these tips to avoid them.
1 Use terminationPolicy: Delete. It is nice to be able to resume the cluster from the previous one. So, we preserve auth Secrets. If you don’t want to resume the cluster, you can just use spec.terminationPolicy: WipeOut. It will clean up every resource that was created with the ConnectCluster CR. For more details, please visit here.
Next Steps
- Quickstart Kafka with KubeDB Operator.
- Quickstart ConnectCluster with KubeDB Operator.
- Use kubedb cli to manage databases like kubectl for Kubernetes.
- Detail concepts of ConnectCluster object.
- Want to hack on KubeDB? Check our contribution guidelines.